 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Unity to Help Solve Intelligence
Nov 18, 2020
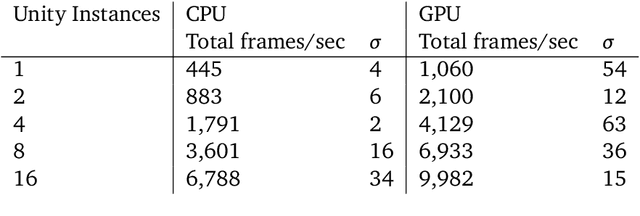
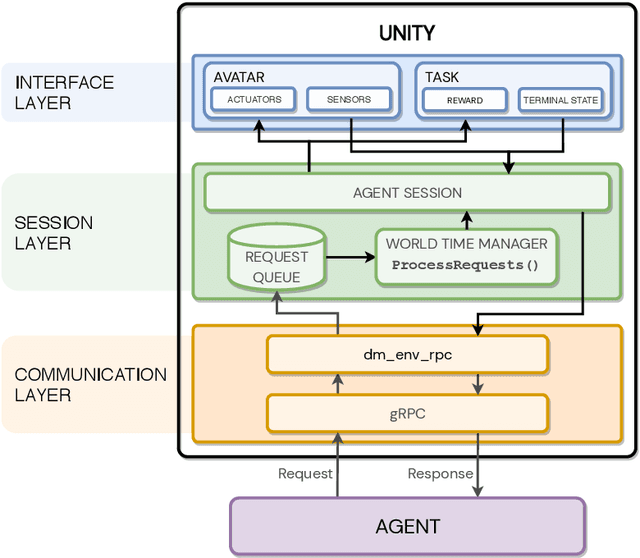

In the pursuit of artificial general intelligence, our most significant measurement of progress is an agent's ability to achieve goals in a wide range of environments. Existing platforms for constructing such environments are typically constrained by the technologies they are founded on, and are therefore only able to provide a subset of scenarios necessary to evaluate progress. To overcome these shortcomings, we present our use of Unity, a widely recognized and comprehensive game engine, to create more diverse, complex, virtual simulations. We describe the concepts and components developed to simplify the authoring of these environments, intended for use predominantly in the field of reinforcement learning. We also introduce a practical approach to packaging and re-distributing environments in a way that attempts to improve the robustness and reproducibility of experiment results. To illustrate the versatility of our use of Unity compared to other solutions, we highlight environments already created using our approach from published papers. We hope that others can draw inspiration from how we adapted Unity to our needs, and anticipate increasingly varied and complex environments to emerge from our approach as familiarity grows.
Emergence of Locomotion Behaviours in Rich Environments
Jul 10, 2017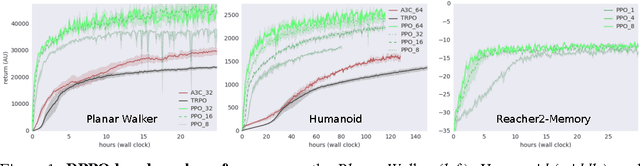
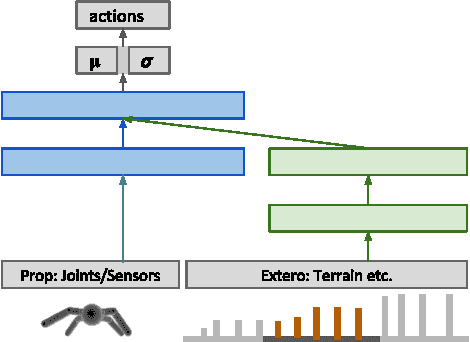


The reinforcement learning paradigm allows, in principle, for complex behaviours to be learned directly from simple reward signals. In practice, however, it is common to carefully hand-design the reward function to encourage a particular solution, or to derive it from demonstration data. In this paper explore how a rich environment can help to promote the learning of complex behavior. Specifically, we train agents in diverse environmental contexts, and find that this encourages the emergence of robust behaviours that perform well across a suite of tasks. We demonstrate this principle for locomotion -- behaviours that are known for their sensitivity to the choice of reward. We train several simulated bodies on a diverse set of challenging terrains and obstacles, using a simple reward function based on forward progress. Using a novel scalable variant of policy gradient reinforcement learning, our agents learn to run, jump, crouch and turn as required by the environment without explicit reward-based guidance. A visual depiction of highlights of the learned behavior can be viewed following https://youtu.be/hx_bgoTF7bs .
Learning human behaviors from motion capture by adversarial imitation
Jul 10, 2017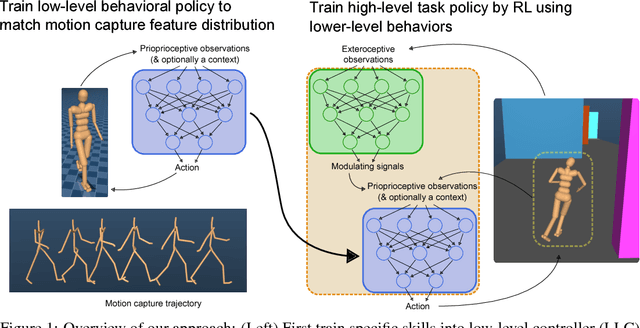
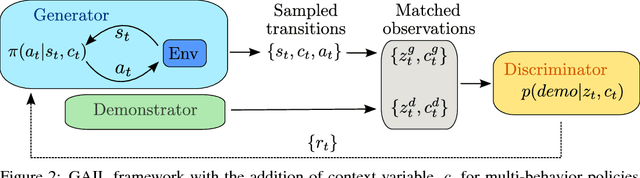
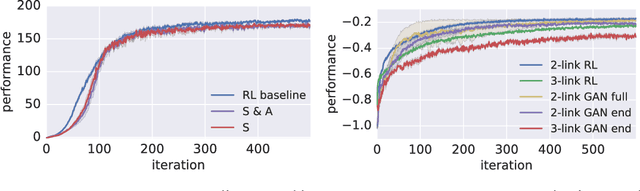
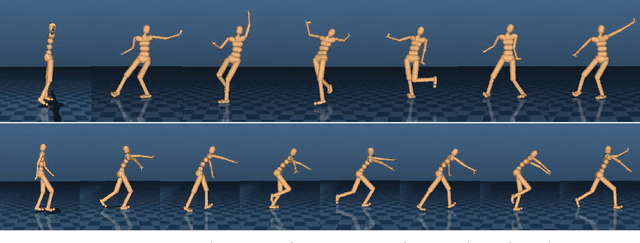
Rapid progress in deep reinforcement learning has made it increasingly feasible to train controllers for high-dimensional humanoid bodies. However, methods that use pure reinforcement learning with simple reward functions tend to produce non-humanlike and overly stereotyped movement behaviors. In this work, we extend generative adversarial imitation learning to enable training of generic neural network policies to produce humanlike movement patterns from limited demonstrations consisting only of partially observed state features, without access to actions, even when the demonstrations come from a body with different and unknown physical parameters. We leverage this approach to build sub-skill policies from motion capture data and show that they can be reused to solve tasks when controlled by a higher level controller.