 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
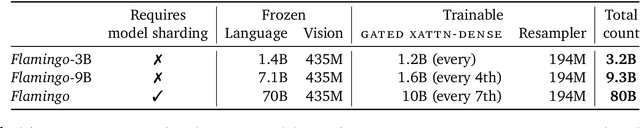
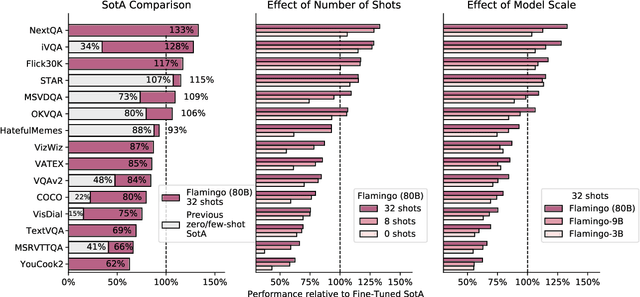
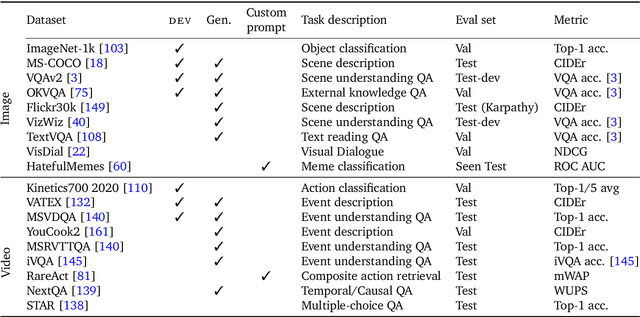
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Using Unity to Help Solve Intelligence
Nov 18, 2020
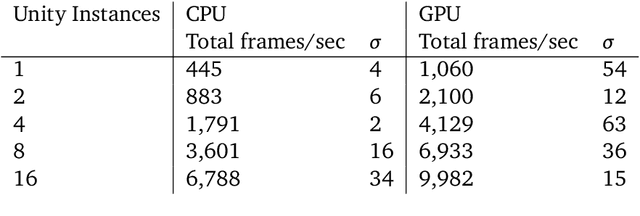
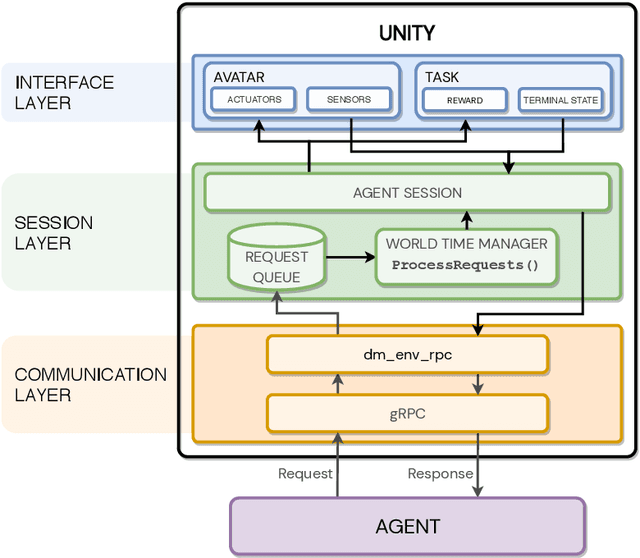

In the pursuit of artificial general intelligence, our most significant measurement of progress is an agent's ability to achieve goals in a wide range of environments. Existing platforms for constructing such environments are typically constrained by the technologies they are founded on, and are therefore only able to provide a subset of scenarios necessary to evaluate progress. To overcome these shortcomings, we present our use of Unity, a widely recognized and comprehensive game engine, to create more diverse, complex, virtual simulations. We describe the concepts and components developed to simplify the authoring of these environments, intended for use predominantly in the field of reinforcement learning. We also introduce a practical approach to packaging and re-distributing environments in a way that attempts to improve the robustness and reproducibility of experiment results. To illustrate the versatility of our use of Unity compared to other solutions, we highlight environments already created using our approach from published papers. We hope that others can draw inspiration from how we adapted Unity to our needs, and anticipate increasingly varied and complex environments to emerge from our approach as familiarity grows.