 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouch-based Curiosity for Sparse-Reward Tasks
Apr 01, 2021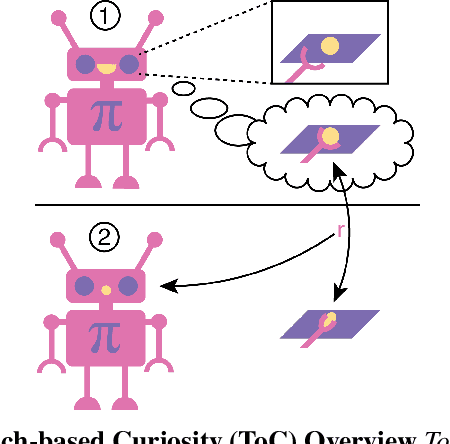
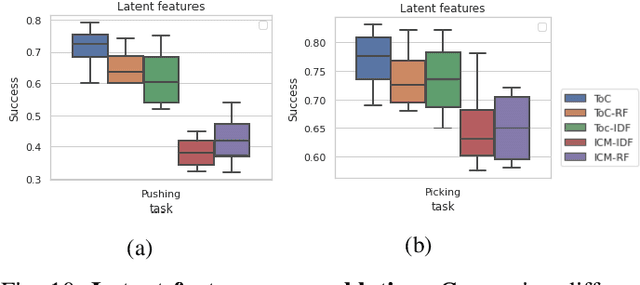
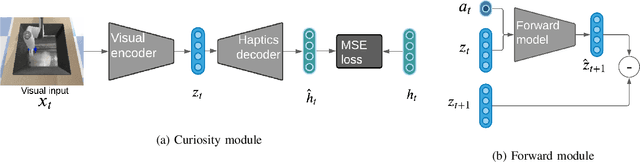
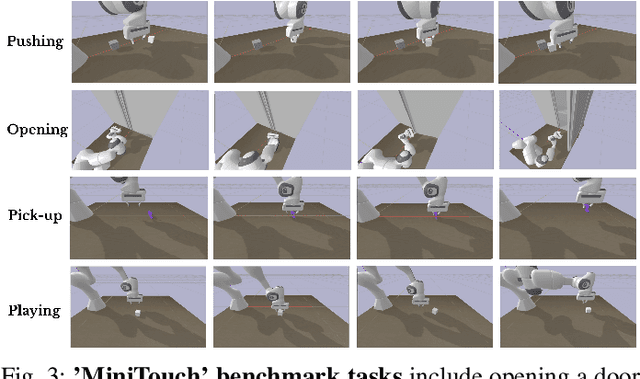
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks that involve contact-rich motion. In this work, we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to "feel" like. We encourage exploration by rewarding interactions where the expectation and the experience don't match. In our proposed method, an initial task-independent exploration phase is followed by an on-task learning phase, in which the original interactions are relabeled with on-task rewards. We test our approach on a range of touch-intensive robot arm tasks (e.g. pushing objects, opening doors), which we also release as part of this work. Across multiple experiments in a simulated setting, we demonstrate that our method is able to learn these difficult tasks through sparse reward and curiosity alone. We compare our cross-modal approach to single-modality (touch- or vision-only) approaches as well as other curiosity-based methods and find that our method performs better and is more sample-efficient.
Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents
Apr 02, 2019
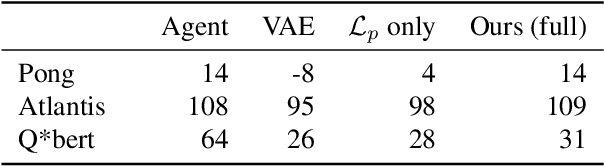


As deep reinforcement learning driven by visual perception becomes more widely used there is a growing need to better understand and probe the learned agents. Understanding the decision making process and its relationship to visual inputs can be very valuable to identify problems in learned behavior. However, this topic has been relatively under-explored in the research community. In this work we present a method for synthesizing visual inputs of interest for a trained agent. Such inputs or states could be situations in which specific actions are necessary. Further, critical states in which a very high or a very low reward can be achieved are often interesting to understand the situational awareness of the system as they can correspond to risky states. To this end, we learn a generative model over the state space of the environment and use its latent space to optimize a target function for the state of interest. In our experiments we show that this method can generate insights for a variety of environments and reinforcement learning methods. We explore results in the standard Atari benchmark games as well as in an autonomous driving simulator. Based on the efficiency with which we have been able to identify behavioural weaknesses with this technique, we believe this general approach could serve as an important tool for AI safety applications.