 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACT: Perception-Action Causal Transformer for Autoregressive Robotics Pre-Training
Sep 23, 2022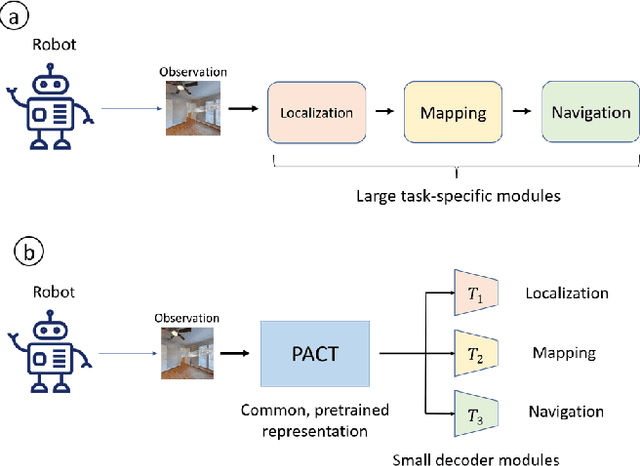
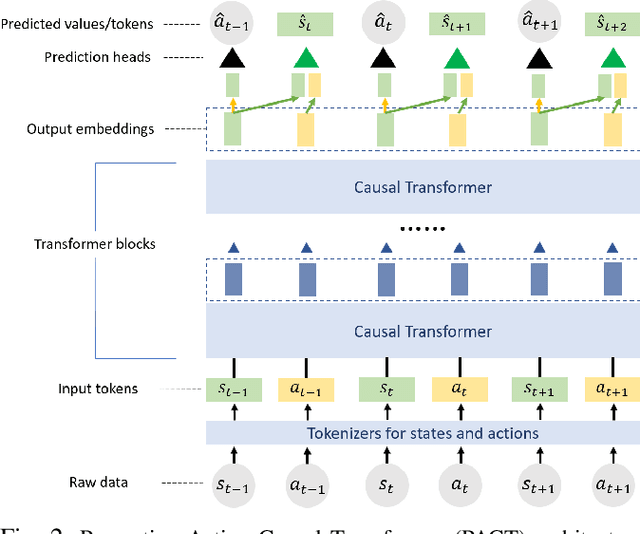
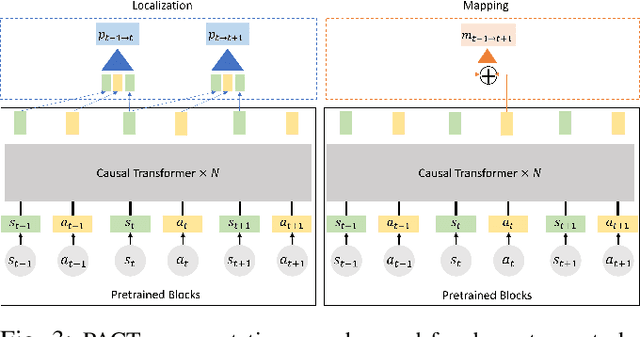

Robotics has long been a field riddled with complex systems architectures whose modules and connections, whether traditional or learning-based, require significant human expertise and prior knowledge. Inspired by large pre-trained language models, this work introduces a paradigm for pre-training a general purpose representation that can serve as a starting point for multiple tasks on a given robot. We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. Our experimental evaluation focuses on the domain of mobile agents, where we show that this robot-specific representation can function as a single starting point to achieve distinct tasks such as safe navigation, localization and mapping. We evaluate two form factors: a wheeled robot that uses a LiDAR sensor as perception input (MuSHR), and a simulated agent that uses first-person RGB images (Habitat). We show that finetuning small task-specific networks on top of the larger pretrained model results in significantly better performance compared to training a single model from scratch for all tasks simultaneously, and comparable performance to training a separate large model for each task independently. By sharing a common good-quality representation across tasks we can lower overall model capacity and speed up the real-time deployment of such systems.
Hindsight Learning for MDPs with Exogenous Inputs
Jul 13, 2022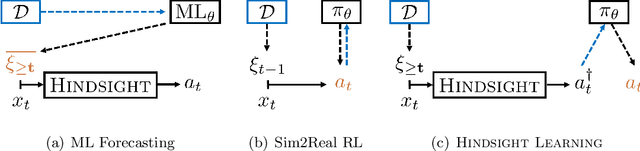


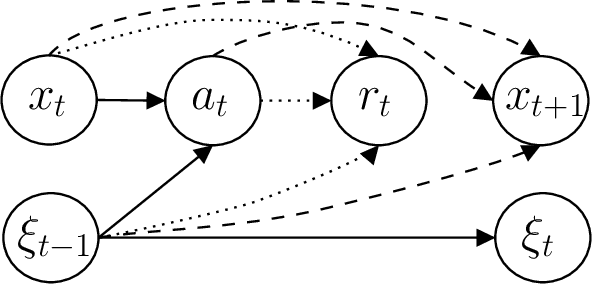
We develop a reinforcement learning (RL) framework for applications that deal with sequential decisions and exogenous uncertainty, such as resource allocation and inventory management. In these applications, the uncertainty is only due to exogenous variables like future demands. A popular approach is to predict the exogenous variables using historical data and then plan with the predictions. However, this indirect approach requires high-fidelity modeling of the exogenous process to guarantee good downstream decision-making, which can be impractical when the exogenous process is complex. In this work we propose an alternative approach based on hindsight learning which sidesteps modeling the exogenous process. Our key insight is that, unlike Sim2Real RL, we can revisit past decisions in the historical data and derive counterfactual consequences for other actions in these applications. Our framework uses hindsight-optimal actions as the policy training signal and has strong theoretical guarantees on decision-making performance. We develop an algorithm using our framework to allocate compute resources for real-world Microsoft Azure workloads. The results show our approach learns better policies than domain-specific heuristics and Sim2Real RL baselines.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022
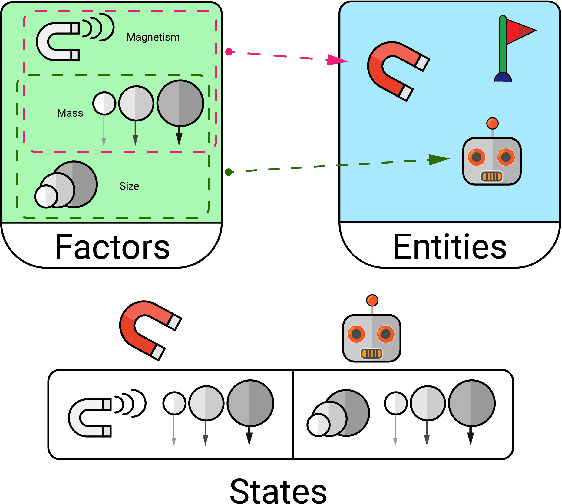
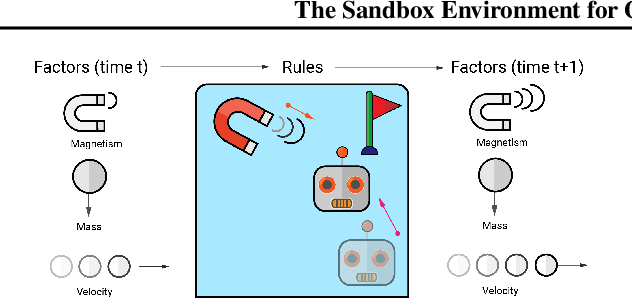
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.