 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sandbox Environment for Generalizable Agent Research (SEGAR)
Paper and Code
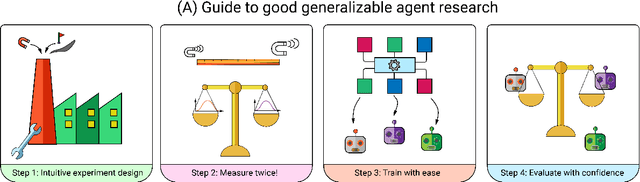
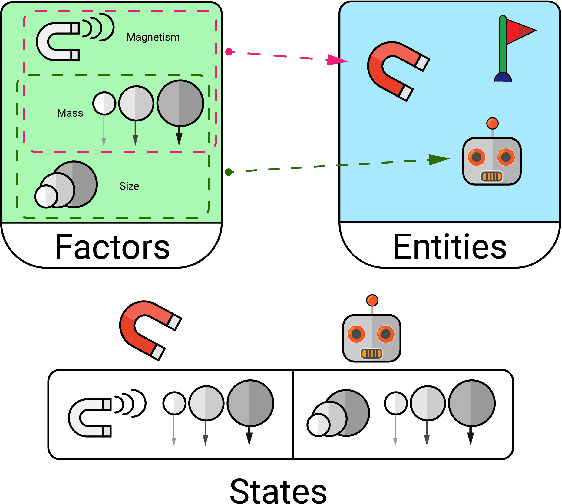
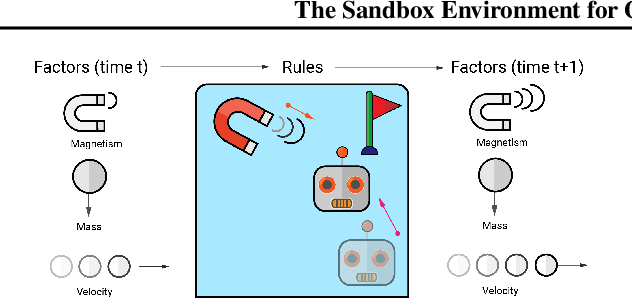
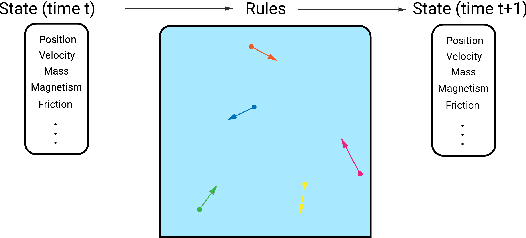
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.