 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyAI 1.1
Jul 24, 2020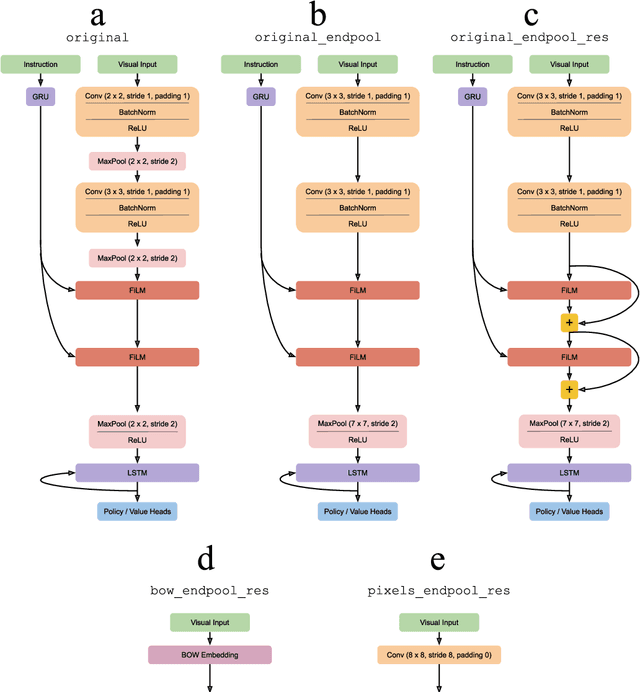
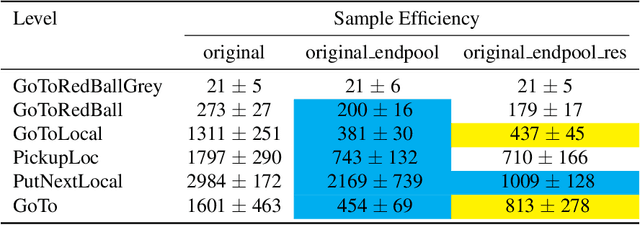

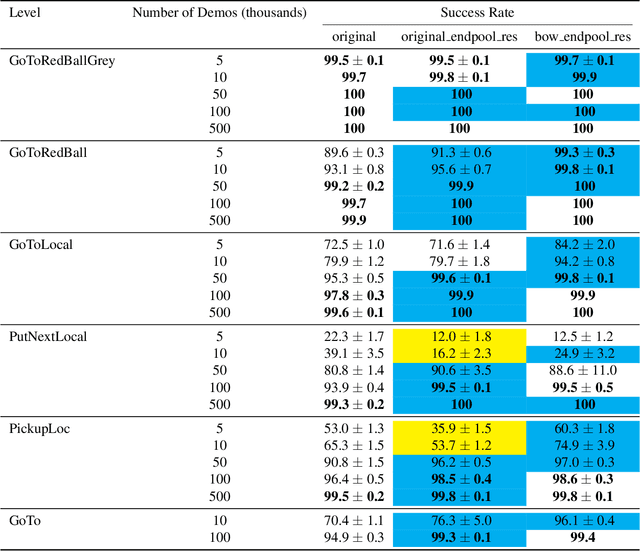
The BabyAI platform is designed to measure the sample efficiency of training an agent to follow grounded-language instructions. BabyAI 1.0 presents baseline results of an agent trained by deep imitation or reinforcement learning. BabyAI 1.1 improves the agent's architecture in three minor ways. This increases reinforcement learning sample efficiency by up to 3 times and improves imitation learning performance on the hardest level from 77 % to 90.4 %. We hope that these improvements increase the computational efficiency of BabyAI experiments and help users design better agents.
A Benchmark of Medical Out of Distribution Detection
Jul 08, 2020

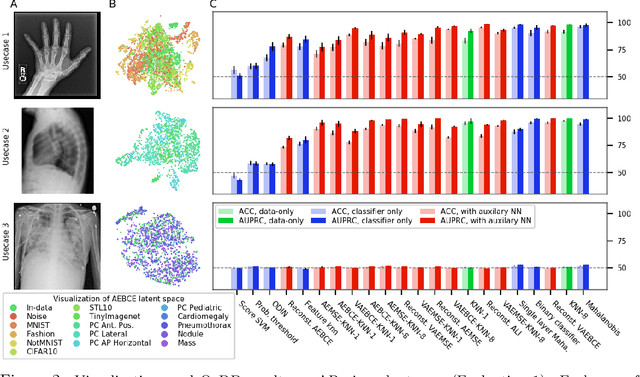
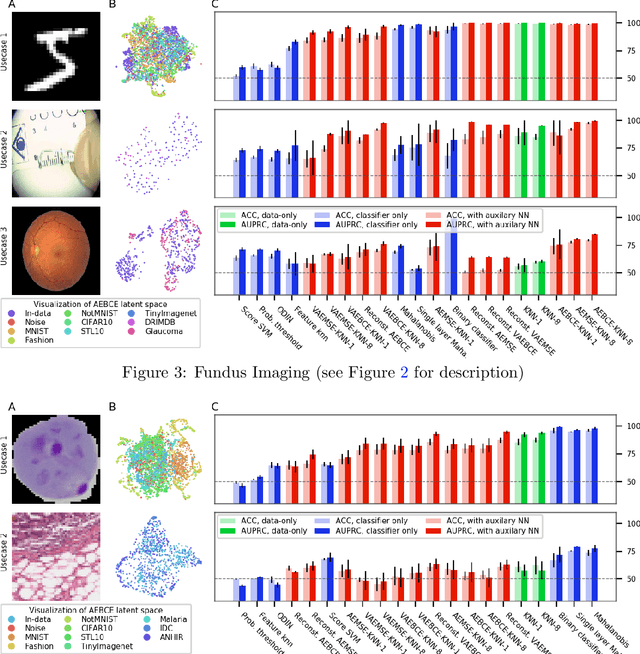
There is a rise in the use of deep learning for automated medical diagnosis, most notably in medical imaging. Such an automated system uses a set of images from a patient to diagnose whether they have a disease. However, systems trained for one particular domain of images cannot be expected to perform accurately on images of a different domain. These images should be filtered out by an Out-of-Distribution Detection (OoDD) method prior to diagnosis. This paper benchmarks popular OoDD methods in three domains of medical imaging: chest x-rays, fundus images, and histology slides. Our experiments show that despite methods yielding good results on some types of out-of-distribution samples, they fail to recognize images close to the training distribution.
Combating False Negatives in Adversarial Imitation Learning
Feb 02, 2020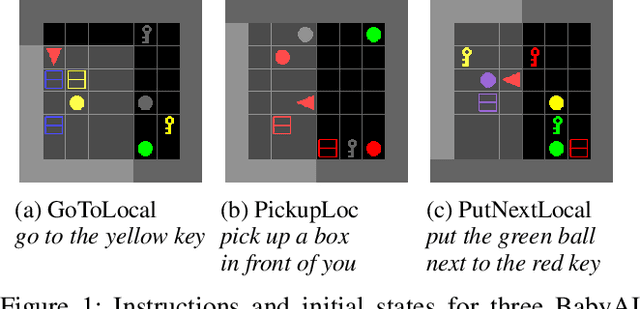

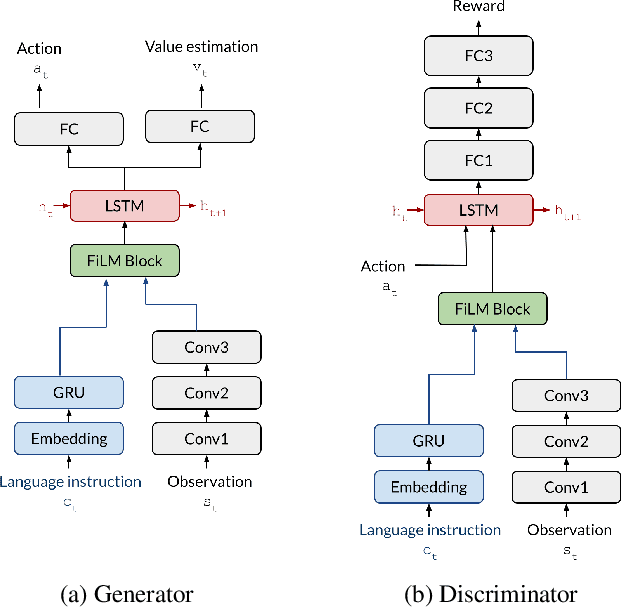
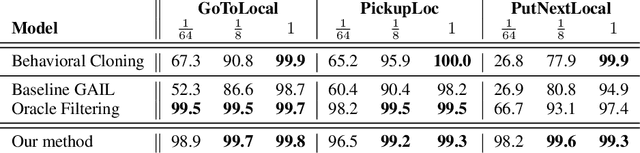
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.