 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Interpretability for Neural TSP Solvers
Oct 24, 2025Neural networks have advanced combinatorial optimization, with Transformer-based solvers achieving near-optimal solutions on the Traveling Salesman Problem (TSP) in milliseconds. However, these models operate as black boxes, providing no insight into the geometric patterns they learn or the heuristics they employ during tour construction. We address this opacity by applying sparse autoencoders (SAEs), a mechanistic interpretability technique, to a Transformer-based TSP solver, representing the first application of activation-based interpretability methods to operations research models. We train a pointer network with reinforcement learning on 100-node instances, then fit an SAE to the encoder's residual stream to discover an overcomplete dictionary of interpretable features. Our analysis reveals that the solver naturally develops features mirroring fundamental TSP concepts: boundary detectors that activate on convex-hull nodes, cluster-sensitive features responding to locally dense regions, and separator features encoding geometric partitions. These findings provide the first model-internal account of what neural TSP solvers compute before node selection, demonstrate that geometric structure emerges without explicit supervision, and suggest pathways toward transparent hybrid systems that combine neural efficiency with algorithmic interpretability. Interactive feature explorer: https://reubennarad.github.io/TSP_interp
From Large Language Models and Optimization to Decision Optimization CoPilot: A Research Manifesto
Feb 26, 2024



Significantly simplifying the creation of optimization models for real-world business problems has long been a major goal in applying mathematical optimization more widely to important business and societal decisions. The recent capabilities of Large Language Models (LLMs) present a timely opportunity to achieve this goal. Therefore, we propose research at the intersection of LLMs and optimization to create a Decision Optimization CoPilot (DOCP) - an AI tool designed to assist any decision maker, interacting in natural language to grasp the business problem, subsequently formulating and solving the corresponding optimization model. This paper outlines our DOCP vision and identifies several fundamental requirements for its implementation. We describe the state of the art through a literature survey and experiments using ChatGPT. We show that a) LLMs already provide substantial novel capabilities relevant to a DOCP, and b) major research challenges remain to be addressed. We also propose possible research directions to overcome these gaps. We also see this work as a call to action to bring together the LLM and optimization communities to pursue our vision, thereby enabling much more widespread improved decision-making.
Ensemble Modeling for Time Series Forecasting: an Adaptive Robust Optimization Approach
Apr 09, 2023Accurate time series forecasting is critical for a wide range of problems with temporal data. Ensemble modeling is a well-established technique for leveraging multiple predictive models to increase accuracy and robustness, as the performance of a single predictor can be highly variable due to shifts in the underlying data distribution. This paper proposes a new methodology for building robust ensembles of time series forecasting models. Our approach utilizes Adaptive Robust Optimization (ARO) to construct a linear regression ensemble in which the models' weights can adapt over time. We demonstrate the effectiveness of our method through a series of synthetic experiments and real-world applications, including air pollution management, energy consumption forecasting, and tropical cyclone intensity forecasting. Our results show that our adaptive ensembles outperform the best ensemble member in hindsight by 16-26% in root mean square error and 14-28% in conditional value at risk and improve over competitive ensemble techniques.
Reducing Air Pollution through Machine Learning
Mar 22, 2023This paper presents a data-driven approach to mitigate the effects of air pollution from industrial plants on nearby cities by linking operational decisions with weather conditions. Our method combines predictive and prescriptive machine learning models to forecast short-term wind speed and direction and recommend operational decisions to reduce or pause the industrial plant's production. We exhibit several trade-offs between reducing environmental impact and maintaining production activities. The predictive component of our framework employs various machine learning models, such as gradient-boosted tree-based models and ensemble methods, for time series forecasting. The prescriptive component utilizes interpretable optimal policy trees to propose multiple trade-offs, such as reducing dangerous emissions by 33-47% and unnecessary costs by 40-63%. Our deployed models significantly reduced forecasting errors, with a range of 38-52% for less than 12-hour lead time and 14-46% for 12 to 48-hour lead time compared to official weather forecasts. We have successfully implemented the predictive component at the OCP Safi site, which is Morocco's largest chemical industrial plant, and are currently in the process of deploying the prescriptive component. Our framework enables sustainable industrial development by eliminating the pollution-industrial activity trade-off through data-driven weather-based operational decisions, significantly enhancing factory optimization and sustainability. This modernizes factory planning and resource allocation while maintaining environmental compliance. The predictive component has boosted production efficiency, leading to cost savings and reduced environmental impact by minimizing air pollution.
oIRL: Robust Adversarial Inverse Reinforcement Learning with Temporally Extended Actions
Feb 20, 2020
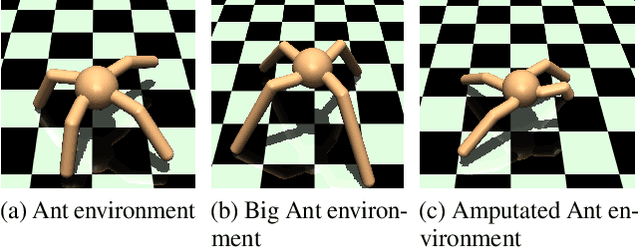

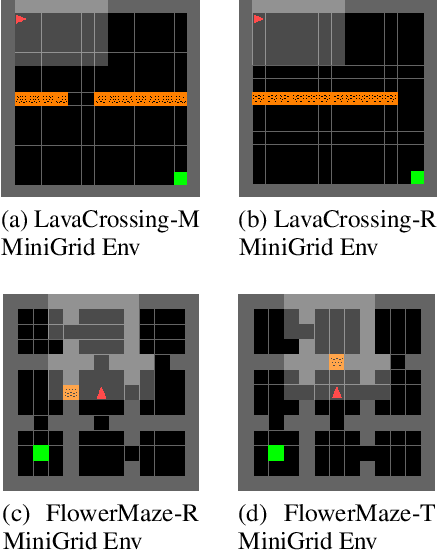
Explicit engineering of reward functions for given environments has been a major hindrance to reinforcement learning methods. While Inverse Reinforcement Learning (IRL) is a solution to recover reward functions from demonstrations only, these learned rewards are generally heavily \textit{entangled} with the dynamics of the environment and therefore not portable or \emph{robust} to changing environments. Modern adversarial methods have yielded some success in reducing reward entanglement in the IRL setting. In this work, we leverage one such method, Adversarial Inverse Reinforcement Learning (AIRL), to propose an algorithm that learns hierarchical disentangled rewards with a policy over options. We show that this method has the ability to learn \emph{generalizable} policies and reward functions in complex transfer learning tasks, while yielding results in continuous control benchmarks that are comparable to those of the state-of-the-art methods.
Combating False Negatives in Adversarial Imitation Learning
Feb 02, 2020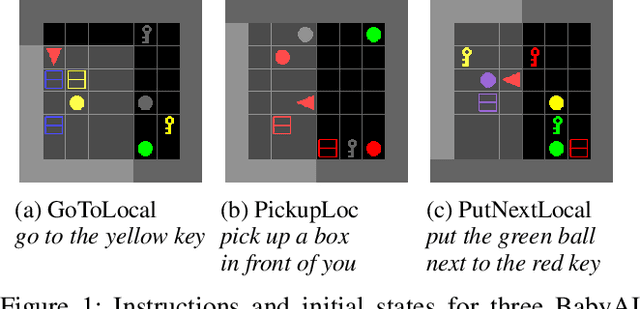

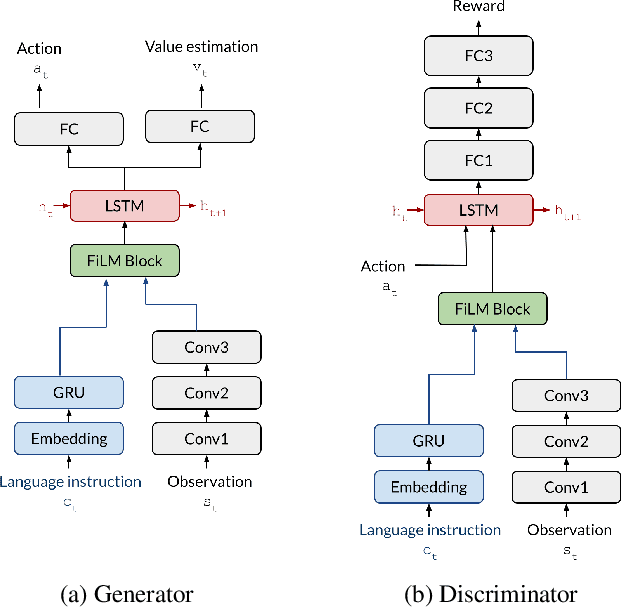
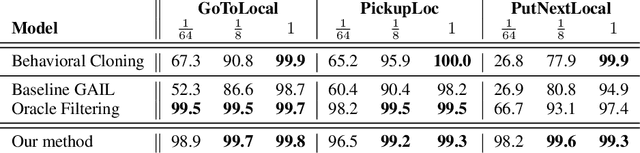
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.
Avoidance Learning Using Observational Reinforcement Learning
Sep 24, 2019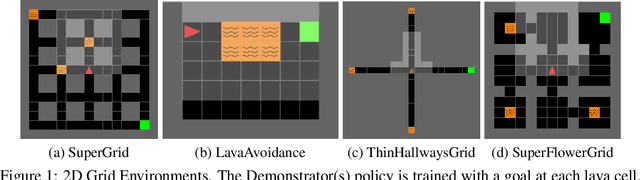
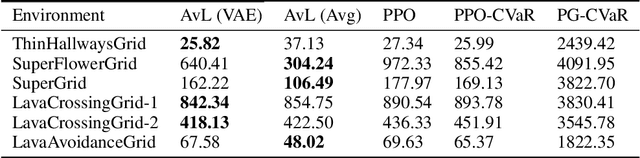


Imitation learning seeks to learn an expert policy from sampled demonstrations. However, in the real world, it is often difficult to find a perfect expert and avoiding dangerous behaviors becomes relevant for safety reasons. We present the idea of \textit{learning to avoid}, an objective opposite to imitation learning in some sense, where an agent learns to avoid a demonstrator policy given an environment. We define avoidance learning as the process of optimizing the agent's reward while avoiding dangerous behaviors given by a demonstrator. In this work we develop a framework of avoidance learning by defining a suitable objective function for these problems which involves the \emph{distance} of state occupancy distributions of the expert and demonstrator policies. We use density estimates for state occupancy measures and use the aforementioned distance as the reward bonus for avoiding the demonstrator. We validate our theory with experiments using a wide range of partially observable environments. Experimental results show that we are able to improve sample efficiency during training compared to state of the art policy optimization and safety methods.