 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoidance Learning Using Observational Reinforcement Learning
Sep 24, 2019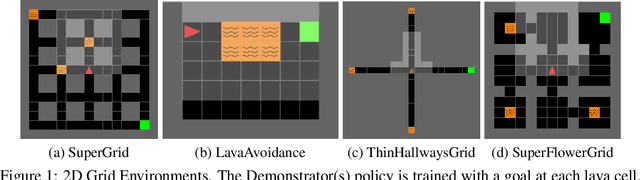
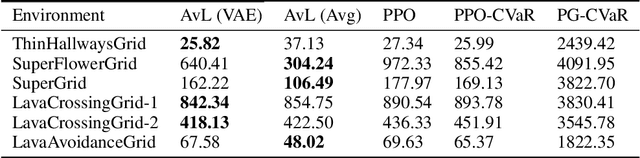


Imitation learning seeks to learn an expert policy from sampled demonstrations. However, in the real world, it is often difficult to find a perfect expert and avoiding dangerous behaviors becomes relevant for safety reasons. We present the idea of \textit{learning to avoid}, an objective opposite to imitation learning in some sense, where an agent learns to avoid a demonstrator policy given an environment. We define avoidance learning as the process of optimizing the agent's reward while avoiding dangerous behaviors given by a demonstrator. In this work we develop a framework of avoidance learning by defining a suitable objective function for these problems which involves the \emph{distance} of state occupancy distributions of the expert and demonstrator policies. We use density estimates for state occupancy measures and use the aforementioned distance as the reward bonus for avoiding the demonstrator. We validate our theory with experiments using a wide range of partially observable environments. Experimental results show that we are able to improve sample efficiency during training compared to state of the art policy optimization and safety methods.