 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Performance of Multilingual NLP Models
Paper and Code
Oct 17, 2021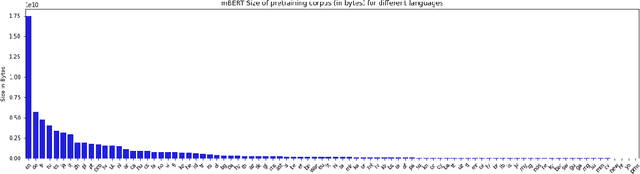
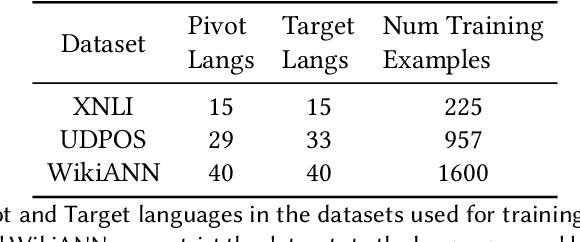
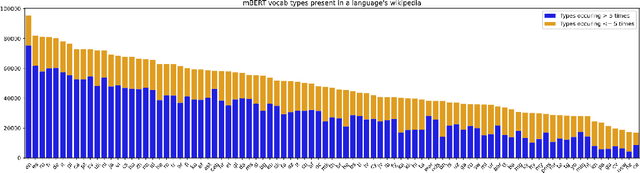
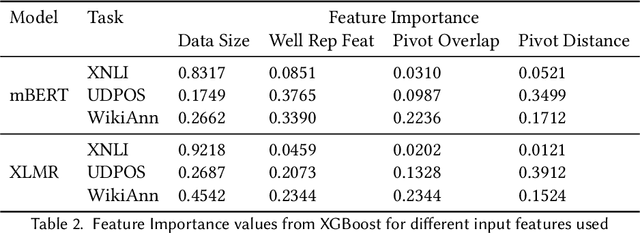
Recent advancements in NLP have given us models like mBERT and XLMR that can serve over 100 languages. The languages that these models are evaluated on, however, are very few in number, and it is unlikely that evaluation datasets will cover all the languages that these models support. Potential solutions to the costly problem of dataset creation are to translate datasets to new languages or use template-filling based techniques for creation. This paper proposes an alternate solution for evaluating a model across languages which make use of the existing performance scores of the model on languages that a particular task has test sets for. We train a predictor on these performance scores and use this predictor to predict the model's performance in different evaluation settings. Our results show that our method is effective in filling the gaps in the evaluation for an existing set of languages, but might require additional improvements if we want it to generalize to unseen languages.