 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Hyperbolic Neural Networks using Taylor Series Approximations
Paper and Code
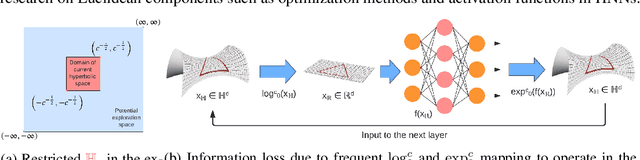
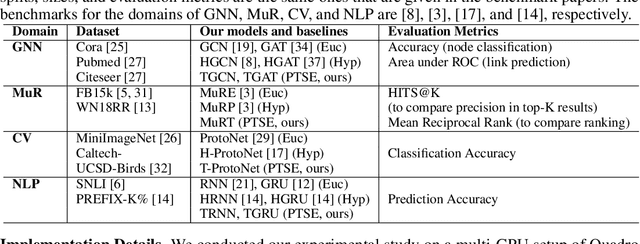
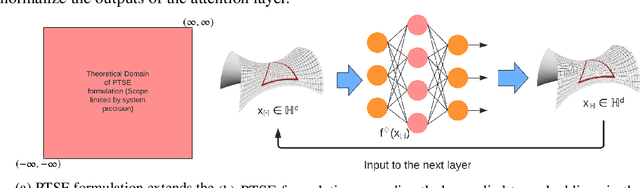
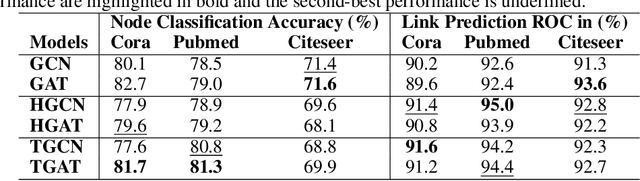
Hyperbolic networks have shown prominent improvements over their Euclidean counterparts in several areas involving hierarchical datasets in various domains such as computer vision, graph analysis, and natural language processing. However, their adoption in practice remains restricted due to (i) non-scalability on accelerated deep learning hardware, (ii) vanishing gradients due to the closure of hyperbolic space, and (iii) information loss due to frequent mapping between local tangent space and fully hyperbolic space. To tackle these issues, we propose the approximation of hyperbolic operators using Taylor series expansions, which allows us to reformulate the computationally expensive tangent and cosine hyperbolic functions into their polynomial equivariants which are more efficient. This allows us to retain the benefits of preserving the hierarchical anatomy of the hyperbolic space, while maintaining the scalability over current accelerated deep learning infrastructure. The polynomial formulation also enables us to utilize the advancements in Euclidean networks such as gradient clipping and ReLU activation to avoid vanishing gradients and remove errors due to frequent switching between tangent space and hyperbolic space. Our empirical evaluation on standard benchmarks in the domain of graph analysis and computer vision shows that our polynomial formulation is as scalable as Euclidean architectures, both in terms of memory and time complexity, while providing results as effective as hyperbolic models. Moreover, our formulation also shows a considerable improvement over its baselines due to our solution to vanishing gradients and information loss.