 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPIServe: Efficient API Support for Large-Language Model Inferencing
Paper and Code
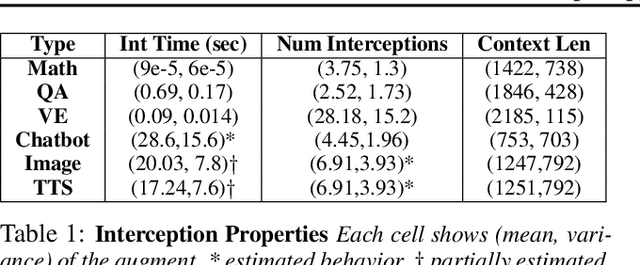
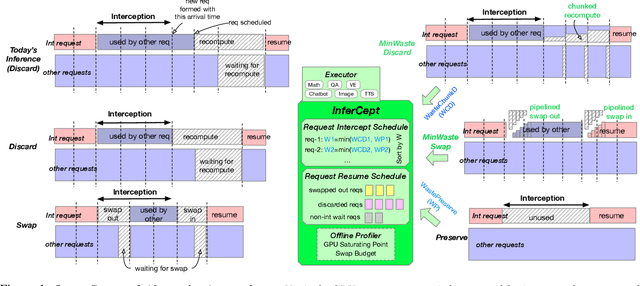
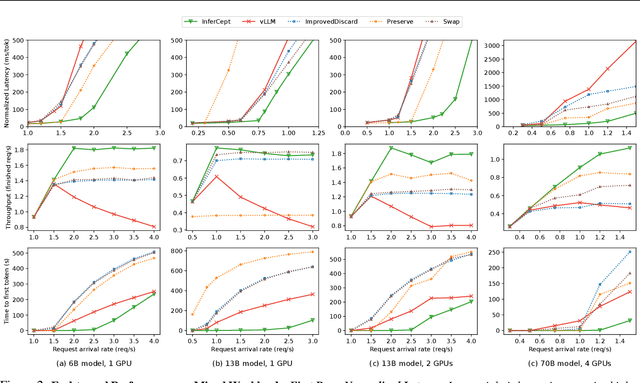
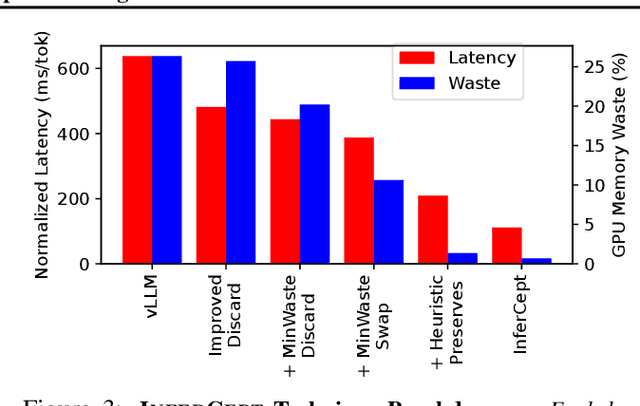
Large language models are increasingly integrated with external tools and APIs like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today's LLM inference systems are designed for standalone LLMs. They treat API calls as new requests, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents APIServe, the first LLM inference framework targeting API-augmented LLMs. APISERVE minimizes the GPU resource waste caused by API calls and dedicates saved memory for serving more requests. APISERVE improves the overall serving throughput by 1.6x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.