 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognify: Supercharging Gen-AI Workflows With Hierarchical Autotuning
Feb 12, 2025



Today's gen-AI workflows that involve multiple ML model calls, tool/API calls, data retrieval, or generic code execution are often tuned manually in an ad-hoc way that is both time-consuming and error-prone. In this paper, we propose a systematic approach for automatically tuning gen-AI workflows. Our key insight is that gen-AI workflows can benefit from structure, operator, and prompt changes, but unique properties of gen-AI workflows require new optimization techniques. We propose AdaSeek, an adaptive hierarchical search algorithm for autotuning gen-AI workflows. AdaSeek organizes workflow tuning methods into different layers based on the user-specified total search budget and distributes the budget across different layers based on the complexity of each layer. During its hierarchical search, AdaSeek redistributes the search budget from less useful to more promising tuning configurations based on workflow-level evaluation results. We implement AdaSeek in a workflow autotuning framework called Cognify and evaluate Cognify using six types of workflows such as RAG-based QA and text-to-SQL transformation. Overall, Cognify improves these workflows' generation quality by up to 2.8x, reduces execution monetary cost by up to 10x, and reduces end-to-end latency by 2.7x.
APIServe: Efficient API Support for Large-Language Model Inferencing
Feb 02, 2024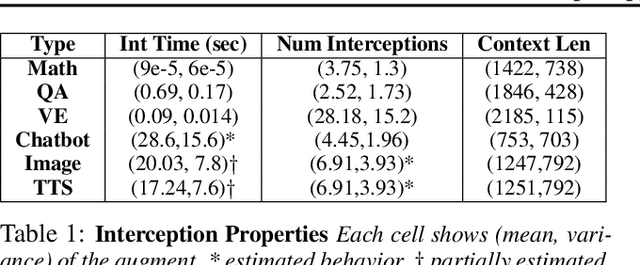
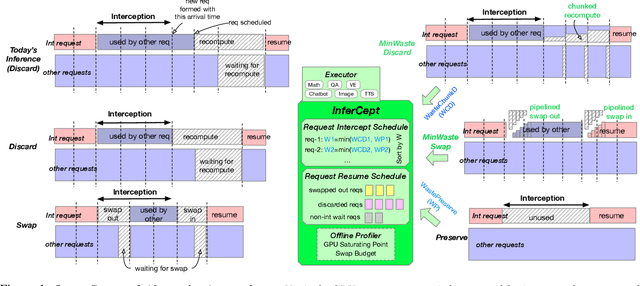
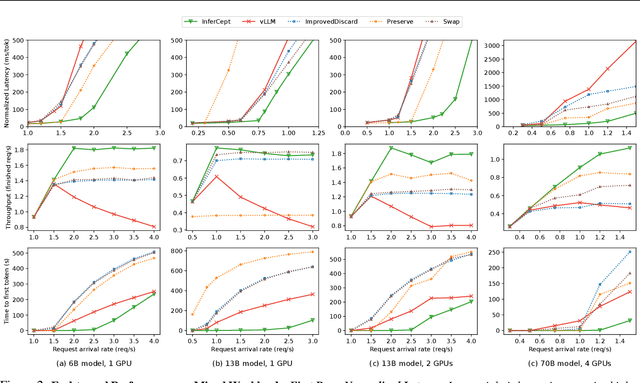
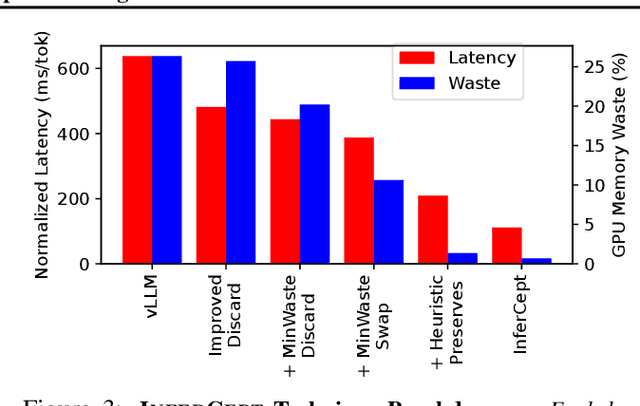
Large language models are increasingly integrated with external tools and APIs like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today's LLM inference systems are designed for standalone LLMs. They treat API calls as new requests, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents APIServe, the first LLM inference framework targeting API-augmented LLMs. APISERVE minimizes the GPU resource waste caused by API calls and dedicates saved memory for serving more requests. APISERVE improves the overall serving throughput by 1.6x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
May 16, 2023



The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. This paper introduces SpecInfer, an LLM serving system that accelerates generative LLM inference with speculative inference and token tree verification. A key insight behind SpecInfer is to combine various collectively boost-tuned small language models to jointly predict the LLM's outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified by the LLM in parallel using a novel tree-based parallel decoding mechanism. SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which significantly reduces the end-to-end latency and computational requirement for serving generative LLMs while provably preserving model quality.