 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning
Paper and Code

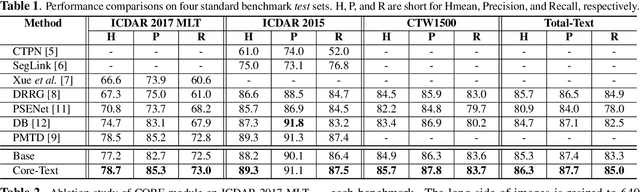
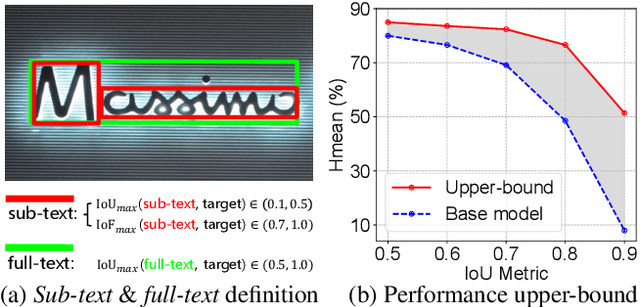
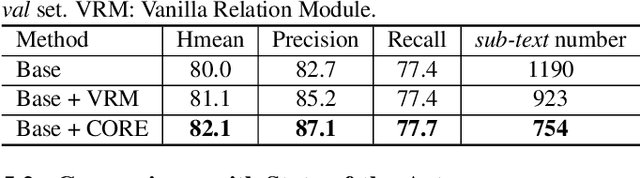
Localizing text instances in natural scenes is regarded as a fundamental challenge in computer vision. Nevertheless, owing to the extremely varied aspect ratios and scales of text instances in real scenes, most conventional text detectors suffer from the sub-text problem that only localizes the fragments of text instance (i.e., sub-texts). In this work, we quantitatively analyze the sub-text problem and present a simple yet effective design, COntrastive RElation (CORE) module, to mitigate that issue. CORE first leverages a vanilla relation block to model the relations among all text proposals (sub-texts of multiple text instances) and further enhances relational reasoning via instance-level sub-text discrimination in a contrastive manner. Such way naturally learns instance-aware representations of text proposals and thus facilitates scene text detection. We integrate the CORE module into a two-stage text detector of Mask R-CNN and devise our text detector CORE-Text. Extensive experiments on four benchmarks demonstrate the superiority of CORE-Text. Code is available: \url{https://github.com/jylins/CORE-Text}.