 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTINQ: Temporal Inconsistency Guided Blind Video Quality Assessment
Dec 25, 2024Blind video quality assessment (BVQA) has been actively researched for user-generated content (UGC) videos. Recently, super-resolution (SR) techniques have been widely applied in UGC. Therefore, an effective BVQA method for both UGC and SR scenarios is essential. Temporal inconsistency, referring to irregularities between consecutive frames, is relevant to video quality. Current BVQA approaches typically model temporal relationships in UGC videos using statistics of motion information, but inconsistencies remain unexplored. Additionally, different from temporal inconsistency in UGC videos, such inconsistency in SR videos is amplified due to upscaling algorithms. In this paper, we introduce the Temporal Inconsistency Guided Blind Video Quality Assessment (TINQ) metric, demonstrating that exploring temporal inconsistency is crucial for effective BVQA. Since temporal inconsistencies vary between UGC and SR videos, they are calculated in different ways. Based on this, a spatial module highlights inconsistent areas across consecutive frames at coarse and fine granularities. In addition, a temporal module aggregates features over time in two stages. The first stage employs a visual memory capacity block to adaptively segment the time dimension based on estimated complexity, while the second stage focuses on selecting key features. The stages work together through Consistency-aware Fusion Units to regress cross-time-scale video quality. Extensive experiments on UGC and SR video quality datasets show that our method outperforms existing state-of-the-art BVQA methods. Code is available at https://github.com/Lighting-YXLI/TINQ.
A Benchmarking Protocol for SAR Colorization: From Regression to Deep Learning Approaches
Oct 12, 2023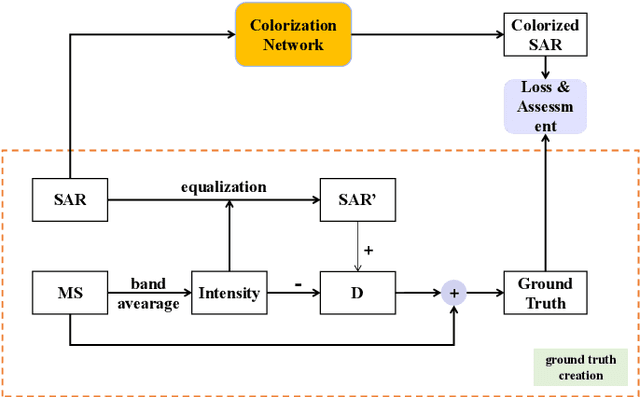



Synthetic aperture radar (SAR) images are widely used in remote sensing. Interpreting SAR images can be challenging due to their intrinsic speckle noise and grayscale nature. To address this issue, SAR colorization has emerged as a research direction to colorize gray scale SAR images while preserving the original spatial information and radiometric information. However, this research field is still in its early stages, and many limitations can be highlighted. In this paper, we propose a full research line for supervised learning-based approaches to SAR colorization. Our approach includes a protocol for generating synthetic color SAR images, several baselines, and an effective method based on the conditional generative adversarial network (cGAN) for SAR colorization. We also propose numerical assessment metrics for the problem at hand. To our knowledge, this is the first attempt to propose a research line for SAR colorization that includes a protocol, a benchmark, and a complete performance evaluation. Our extensive tests demonstrate the effectiveness of our proposed cGAN-based network for SAR colorization. The code will be made publicly available.
A One-dimensional HEVC video steganalysis method using the Optimality of Predicted Motion Vectors
Aug 12, 2023Among steganalysis techniques, detection against motion vector (MV) domain-based video steganography in High Efficiency Video Coding (HEVC) standard remains a hot and challenging issue. For the purpose of improving the detection performance, this paper proposes a steganalysis feature based on the optimality of predicted MVs with a dimension of one. Firstly, we point out that the motion vector prediction (MVP) of the prediction unit (PU) encoded using the Advanced Motion Vector Prediction (AMVP) technique satisfies the local optimality in the cover video. Secondly, we analyze that in HEVC video, message embedding either using MVP index or motion vector differences (MVD) may destroy the above optimality of MVP. And then, we define the optimal rate of MVP in HEVC video as a steganalysis feature. Finally, we conduct steganalysis detection experiments on two general datasets for three popular steganography methods and compare the performance with four state-of-the-art steganalysis methods. The experimental results show that the proposed optimal rate of MVP for all cover videos is 100\%, while the optimal rate of MVP for all stego videos is less than 100\%. Therefore, the proposed steganography scheme can accurately distinguish between cover videos and stego videos, and it is efficiently applied to practical scenarios with no model training and low computational complexity.