 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTINQ: Temporal Inconsistency Guided Blind Video Quality Assessment
Dec 25, 2024Blind video quality assessment (BVQA) has been actively researched for user-generated content (UGC) videos. Recently, super-resolution (SR) techniques have been widely applied in UGC. Therefore, an effective BVQA method for both UGC and SR scenarios is essential. Temporal inconsistency, referring to irregularities between consecutive frames, is relevant to video quality. Current BVQA approaches typically model temporal relationships in UGC videos using statistics of motion information, but inconsistencies remain unexplored. Additionally, different from temporal inconsistency in UGC videos, such inconsistency in SR videos is amplified due to upscaling algorithms. In this paper, we introduce the Temporal Inconsistency Guided Blind Video Quality Assessment (TINQ) metric, demonstrating that exploring temporal inconsistency is crucial for effective BVQA. Since temporal inconsistencies vary between UGC and SR videos, they are calculated in different ways. Based on this, a spatial module highlights inconsistent areas across consecutive frames at coarse and fine granularities. In addition, a temporal module aggregates features over time in two stages. The first stage employs a visual memory capacity block to adaptively segment the time dimension based on estimated complexity, while the second stage focuses on selecting key features. The stages work together through Consistency-aware Fusion Units to regress cross-time-scale video quality. Extensive experiments on UGC and SR video quality datasets show that our method outperforms existing state-of-the-art BVQA methods. Code is available at https://github.com/Lighting-YXLI/TINQ.
Fusion of Short-term and Long-term Attention for Video Mirror Detection
Jul 10, 2024



Techniques for detecting mirrors from static images have witnessed rapid growth in recent years. However, these methods detect mirrors from single input images. Detecting mirrors from video requires further consideration of temporal consistency between frames. We observe that humans can recognize mirror candidates, from just one or two frames, based on their appearance (e.g. shape, color). However, to ensure that the candidate is indeed a mirror (not a picture or a window), we often need to observe more frames for a global view. This observation motivates us to detect mirrors by fusing appearance features extracted from a short-term attention module and context information extracted from a long-term attention module. To evaluate the performance, we build a challenging benchmark dataset of 19,255 frames from 281 videos. Experimental results demonstrate that our method achieves state-of-the-art performance on the benchmark dataset.
HDFD --- A High Deformation Facial Dynamics Benchmark for Evaluation of Non-Rigid Surface Registration and Classification
Jul 09, 2018
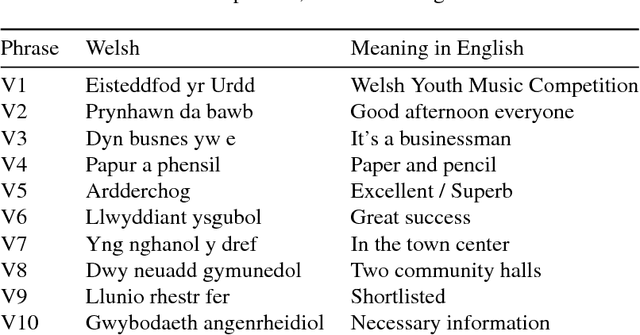

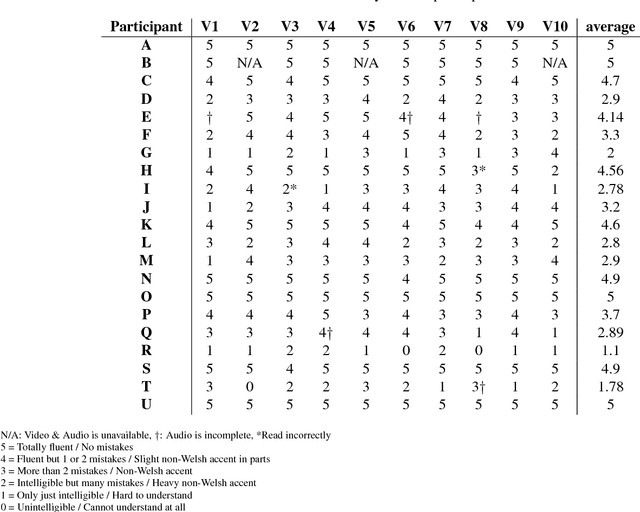
Objects that undergo non-rigid deformation are common in the real world. A typical and challenging example is the human faces. While various techniques have been developed for deformable shape registration and classification, benchmarks with detailed labels and landmarks suitable for evaluating such techniques are still limited. In this paper, we present a novel facial dynamic dataset HDFD which addresses the gap of existing datasets, including 4D funny faces with substantial non-isometric deformation, and 4D visual-audio faces of spoken phrases in a minority language (Welsh). Both datasets are captured from 21 participants. The sequences are manually landmarked, with the spoken phrases further rated by a Welsh expert for level of fluency. These are useful for quantitative evaluation of both registration and classification tasks. We further develop a methodology to evaluate several recent non-rigid surface registration techniques, using our dynamic sequences as test cases. The study demonstrates the significance and usefulness of our new dataset --- a challenging benchmark dataset for future techniques.