 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
Accelerating Diffusion Models via Early Stop of the Diffusion Process
May 30, 2022

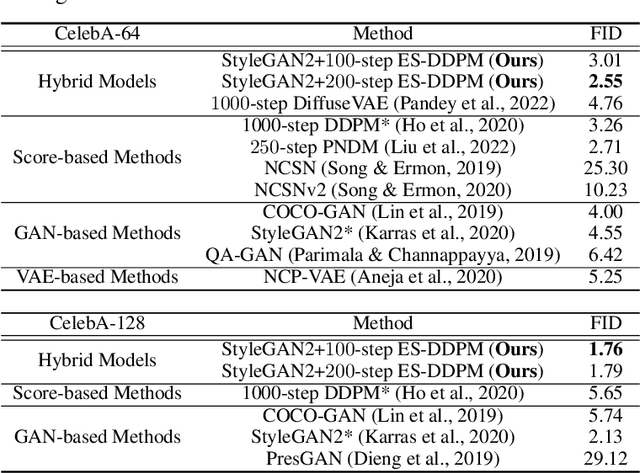
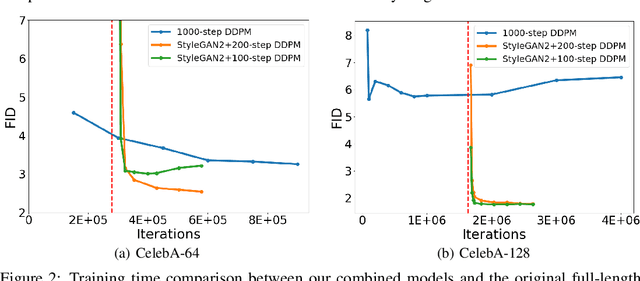
Denoising Diffusion Probabilistic Models (DDPMs) have achieved impressive performance on various generation tasks. By modeling the reverse process of gradually diffusing the data distribution into a Gaussian distribution, generating a sample in DDPMs can be regarded as iteratively denoising a randomly sampled Gaussian noise. However, in practice DDPMs often need hundreds even thousands of denoising steps to obtain a high-quality sample from the Gaussian noise, leading to extremely low inference efficiency. In this work, we propose a principled acceleration strategy, referred to as Early-Stopped DDPM (ES-DDPM), for DDPMs. The key idea is to stop the diffusion process early where only the few initial diffusing steps are considered and the reverse denoising process starts from a non-Gaussian distribution. By further adopting a powerful pre-trained generative model, such as GAN and VAE, in ES-DDPM, sampling from the target non-Gaussian distribution can be efficiently achieved by diffusing samples obtained from the pre-trained generative model. In this way, the number of required denoising steps is significantly reduced. In the meantime, the sample quality of ES-DDPM also improves substantially, outperforming both the vanilla DDPM and the adopted pre-trained generative model. On extensive experiments across CIFAR-10, CelebA, ImageNet, LSUN-Bedroom and LSUN-Cat, ES-DDPM obtains promising acceleration effect and performance improvement over representative baseline methods. Moreover, ES-DDPM also demonstrates several attractive properties, including being orthogonal to existing acceleration methods, as well as simultaneously enabling both global semantic and local pixel-level control in image generation.