 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexFAIR: Better Fairness via Model-based Rebalancing of Protected Attributes
Paper and Code

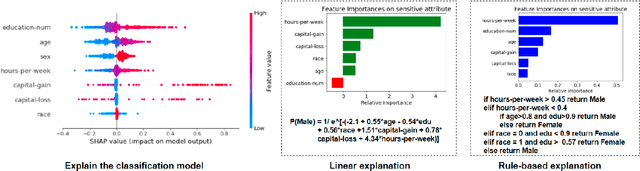

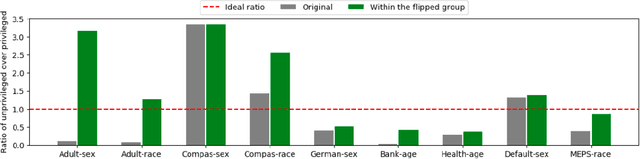
Machine learning software can generate models that inappropriately discriminate against specific protected social groups (e.g., groups based on gender, ethnicity, etc). Motivated by those results, software engineering researchers have proposed many methods for mitigating those discriminatory effects. While those methods are effective in mitigating bias, few of them can provide explanations on what is the cause of bias. Here we propose xFAIR, a model-based extrapolation method, that is capable of both mitigating bias and explaining the cause. In our xFAIR approach, protected attributes are represented by models learned from the other independent variables (and these models offer extrapolations over the space between existing examples). We then use the extrapolation models to relabel protected attributes, which aims to offset the biased predictions of the classification model via rebalancing the distribution of protected attributes. The experiments of this paper show that, without compromising(original) model performance,xFAIRcan achieve significantly better group and individual fairness (as measured in different metrics)than benchmark methods. Moreover, when compared to another instance-based rebalancing method, our model-based approach shows faster runtime and thus better scalability