 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Technical Debt Detection via SURVEYing
May 20, 2019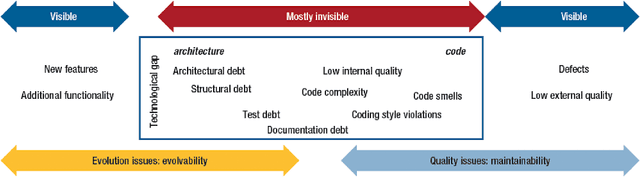
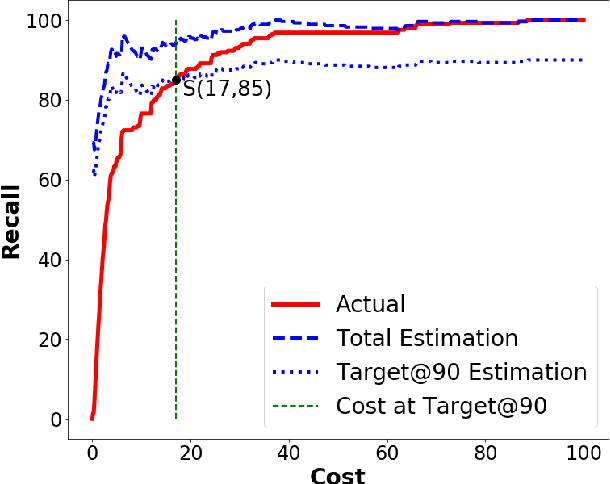
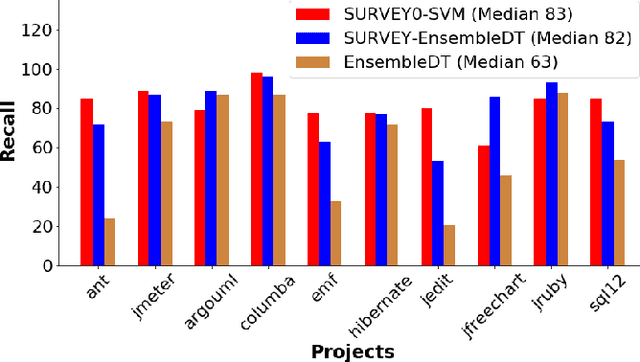
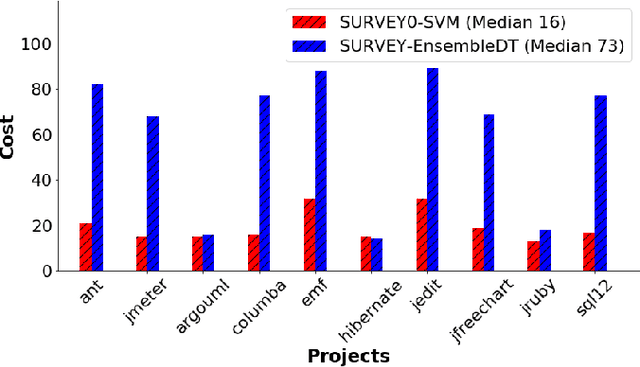
Software analytics can be improved by surveying; i.e. rechecking and (possibly) revising the labels offered by prior analysis. Surveying is a time-consuming task and effective surveyors must carefully manage their time. Specifically, they must balance the cost of further surveying against the additional benefits of that extra effort. This paper proposes SURVEY0, an incremental Logistic Regression estimation method that implements cost/benefit analysis. Some classifier is used to rank the as-yet-unvisited examples according to how interesting they might be. Humans then review the most interesting examples, after which their feedback is used to update an estimator for estimating how many examples are remaining. This paper evaluates SURVEY0 in the context of self-admitted technical debt. As software project mature, they can accumulate "technical debt" i.e. developer decisions which are sub-optimal and decrease the overall quality of the code. Such decisions are often commented on by programmers in the code; i.e. it is self-admitted technical debt (SATD). Recent results show that text classifiers can automatically detect such debt. We find that we can significantly outperform prior results by SURVEYing the data. Specifically, for ten open-source JAVA projects, we can find 83% of the technical debt via SURVEY0 using just 16% of the comments (and if higher levels of recall are required, SURVEY0can adjust towards that with some additional effort).
TERMINATOR: Better Automated UI Test Case Prioritization
May 16, 2019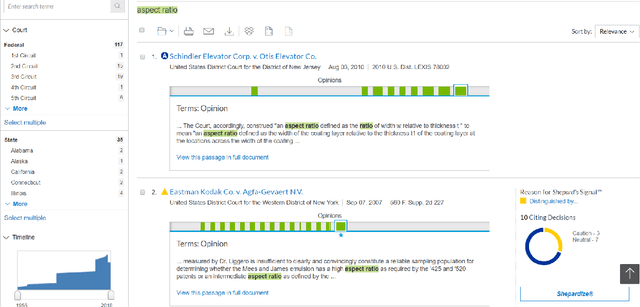


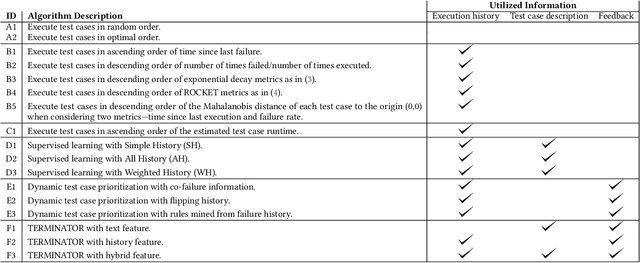
Automated UI testing is an important component of the continuous integration process of software development. A modern web-based UI is an amalgam of reports from dozens of microservices written by multiple teams. Queries on a page that opens up another will fail if any of that page's microservices fails. As a result, the overall cost for automated UI testing is high since the UI elements cannot be tested in isolation. For example, the entire automated UI testing suite at LexisNexis takes around 30 hours (3-5 hours on the cloud) to execute, which slows down the continuous integration process. To mitigate this problem and give developers faster feedback on their code, test case prioritization techniques used to reorder the automated UI test cases so that more failures can be detected earlier. Given that much of the automated UI testing is "black box" in nature, very little information (only the test case descriptions and testing results) can be utilized to prioritize these automated UI test cases. Hence, this paper evaluates 17 "black box" test case prioritization approaches that do not rely on source code information. Among which, we proposed a novel TCP approach, that dynamically re-prioritizes the test cases when new failures are detected, by applying and adapting the state of the art framework from the total recall problem. Experimental results on LexisNexis automated UI testing data showed that, our new approach (which we call TERMINATOR), outperformed prior state of the art approaches in terms of failure detection rates with negligible CPU overhead.
Software Engineering for Fairness: A Case Study with Hyperparameter Optimization
May 14, 2019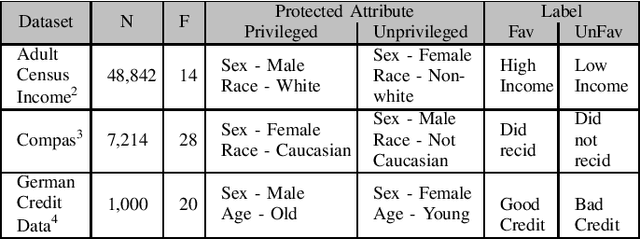
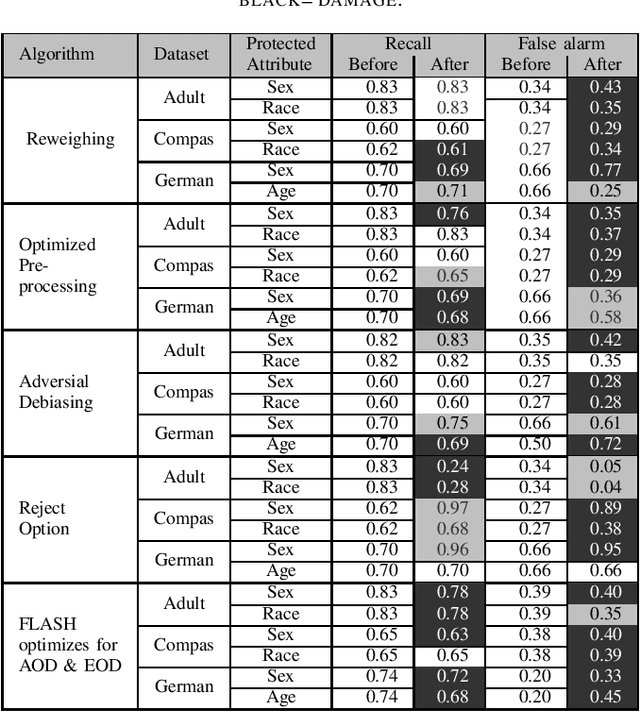
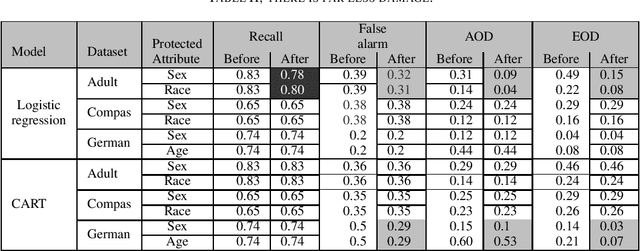
We assert that it is the ethical duty of software engineers to strive to reduce software discrimination. This paper discusses how that might be done. This is an important topic since machine learning software is increasingly being used to make decisions that affect people's lives. Potentially, the application of that software will result in fairer decisions because (unlike humans) machine learning software is not biased. However, recent results show that the software within many data mining packages exhibits "group discrimination"; i.e. their decisions are inappropriately affected by "protected attributes"(e.g., race, gender, age, etc.). There has been much prior work on validating the fairness of machine-learning models (by recognizing when such software discrimination exists). But after detection, comes mitigation. What steps can ethical software engineers take to reduce discrimination in the software they produce? This paper shows that making \textit{fairness} as a goal during hyperparameter optimization can (a) preserve the predictive power of a model learned from a data miner while also (b) generates fairer results. To the best of our knowledge, this is the first application of hyperparameter optimization as a tool for software engineers to generate fairer software.