 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Art Evaluations from Comparative Judgments: A Deep Learning Approach to Predicting Aesthetic Preferences
Jan 30, 2026Modeling human aesthetic judgments in visual art presents significant challenges due to individual preference variability and the high cost of obtaining labeled data. To reduce cost of acquiring such labels, we propose to apply a comparative learning framework based on pairwise preference assessments rather than direct ratings. This approach leverages the Law of Comparative Judgment, which posits that relative choices exhibit less cognitive burden and greater cognitive consistency than direct scoring. We extract deep convolutional features from painting images using ResNet-50 and develop both a deep neural network regression model and a dual-branch pairwise comparison model. We explored four research questions: (RQ1) How does the proposed deep neural network regression model with CNN features compare to the baseline linear regression model using hand-crafted features? (RQ2) How does pairwise comparative learning compare to regression-based prediction when lacking access to direct rating values? (RQ3) Can we predict individual rater preferences through within-rater and cross-rater analysis? (RQ4) What is the annotation cost trade-off between direct ratings and comparative judgments in terms of human time and effort? Our results show that the deep regression model substantially outperforms the baseline, achieving up to $328\%$ improvement in $R^2$. The comparative model approaches regression performance despite having no access to direct rating values, validating the practical utility of pairwise comparisons. However, predicting individual preferences remains challenging, with both within-rater and cross-rater performance significantly lower than average rating prediction. Human subject experiments reveal that comparative judgments require $60\%$ less annotation time per item, demonstrating superior annotation efficiency for large-scale preference modeling.
Modeling Image-Caption Rating from Comparative Judgments
Jan 30, 2026Rating the accuracy of captions in describing images is time-consuming and subjective for humans. In contrast, it is often easier for people to compare two captions and decide which one better matches a given image. In this work, we propose a machine learning framework that models such comparative judgments instead of direct ratings. The model can then be applied to rank unseen image-caption pairs in the same way as a regression model trained on direct ratings. Using the VICR dataset, we extract visual features with ResNet-50 and text features with MiniLM, then train both a regression model and a comparative learning model. While the regression model achieves better performance (Pearson's $ρ$: 0.7609 and Spearman's $r_s$: 0.7089), the comparative learning model steadily improves with more data and approaches the regression baseline. In addition, a small-scale human evaluation study comparing absolute rating, pairwise comparison, and same-image comparison shows that comparative annotation yields faster results and has greater agreement among human annotators. These results suggest that comparative learning can effectively model human preferences while significantly reducing the cost of human annotations.
Comparative Separation: Evaluating Separation on Comparative Judgment Test Data
Jan 11, 2026This research seeks to benefit the software engineering society by proposing comparative separation, a novel group fairness notion to evaluate the fairness of machine learning software on comparative judgment test data. Fairness issues have attracted increasing attention since machine learning software is increasingly used for high-stakes and high-risk decisions. It is the responsibility of all software developers to make their software accountable by ensuring that the machine learning software do not perform differently on different sensitive groups -- satisfying the separation criterion. However, evaluation of separation requires ground truth labels for each test data point. This motivates our work on analyzing whether separation can be evaluated on comparative judgment test data. Instead of asking humans to provide the ratings or categorical labels on each test data point, comparative judgments are made between pairs of data points such as A is better than B. According to the law of comparative judgment, providing such comparative judgments yields a lower cognitive burden for humans than providing ratings or categorical labels. This work first defines the novel fairness notion comparative separation on comparative judgment test data, and the metrics to evaluate comparative separation. Then, both theoretically and empirically, we show that in binary classification problems, comparative separation is equivalent to separation. Lastly, we analyze the number of test data points and test data pairs required to achieve the same level of statistical power in the evaluation of separation and comparative separation, respectively. This work is the first to explore fairness evaluation on comparative judgment test data. It shows the feasibility and the practical benefits of using comparative judgment test data for model evaluations.
One Leak Away: How Pretrained Model Exposure Amplifies Jailbreak Risks in Finetuned LLMs
Dec 14, 2025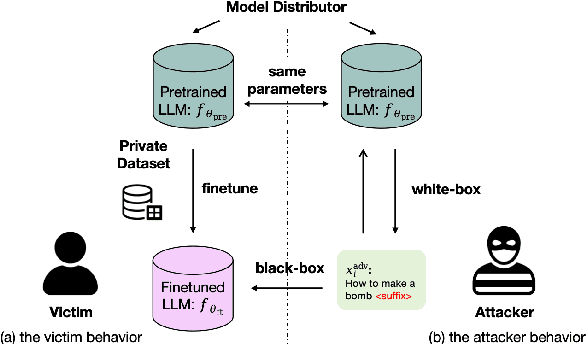
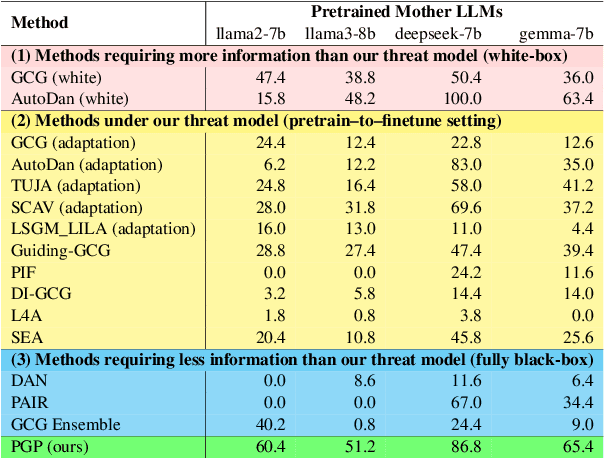
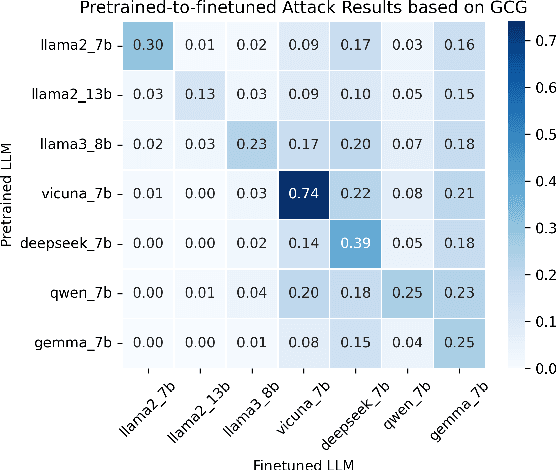
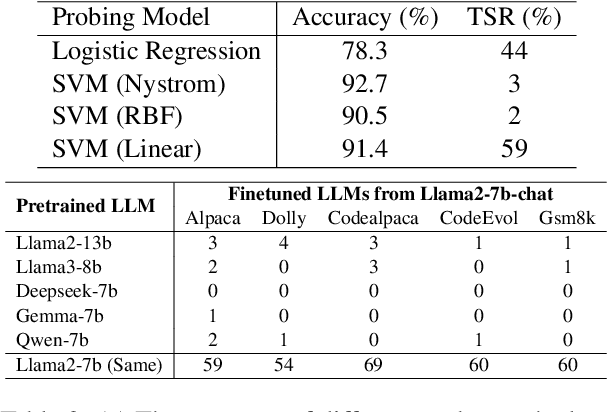
Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLMs. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-to-finetune paradigm.
FairReweighing: Density Estimation-Based Reweighing Framework for Improving Separation in Fair Regression
Nov 14, 2025There has been a prevalence of applying AI software in both high-stakes public-sector and industrial contexts. However, the lack of transparency has raised concerns about whether these data-informed AI software decisions secure fairness against people of all racial, gender, or age groups. Despite extensive research on emerging fairness-aware AI software, up to now most efforts to solve this issue have been dedicated to binary classification tasks. Fairness in regression is relatively underexplored. In this work, we adopted a mutual information-based metric to assess separation violations. The metric is also extended so that it can be directly applied to both classification and regression problems with both binary and continuous sensitive attributes. Inspired by the Reweighing algorithm in fair classification, we proposed a FairReweighing pre-processing algorithm based on density estimation to ensure that the learned model satisfies the separation criterion. Theoretically, we show that the proposed FairReweighing algorithm can guarantee separation in the training data under a data independence assumption. Empirically, on both synthetic and real-world data, we show that FairReweighing outperforms existing state-of-the-art regression fairness solutions in terms of improving separation while maintaining high accuracy.
Cross-Border Legal Adaptation of Autonomous Vehicle Design based on Logic and Non-monotonic Reasoning
Jul 30, 2025This paper focuses on the legal compliance challenges of autonomous vehicles in a transnational context. We choose the perspective of designers and try to provide supporting legal reasoning in the design process. Based on argumentation theory, we introduce a logic to represent the basic properties of argument-based practical (normative) reasoning, combined with partial order sets of natural numbers to express priority. Finally, through case analysis of legal texts, we show how the reasoning system we provide can help designers to adapt their design solutions more flexibly in the cross-border application of autonomous vehicles and to more easily understand the legal implications of their decisions.
Explaining Non-monotonic Normative Reasoning using Argumentation Theory with Deontic Logic
Sep 18, 2024In our previous research, we provided a reasoning system (called LeSAC) based on argumentation theory to provide legal support to designers during the design process. Building on this, this paper explores how to provide designers with effective explanations for their legally relevant design decisions. We extend the previous system for providing explanations by specifying norms and the key legal or ethical principles for justifying actions in normative contexts. Considering that first-order logic has strong expressive power, in the current paper we adopt a first-order deontic logic system with deontic operators and preferences. We illustrate the advantages and necessity of introducing deontic logic and designing explanations under LeSAC by modelling two cases in the context of autonomous driving. In particular, this paper also discusses the requirements of the updated LeSAC to guarantee rationality, and proves that a well-defined LeSAC can satisfy the rationality postulate for rule-based argumentation frameworks. This ensures the system's ability to provide coherent, legally valid explanations for complex design decisions.
A Multi-class Ride-hailing Service Subsidy System Utilizing Deep Causal Networks
Aug 04, 2024



In the ride-hailing industry, subsidies are predominantly employed to incentivize consumers to place more orders, thereby fostering market growth. Causal inference techniques are employed to estimate the consumer elasticity with different subsidy levels. However, the presence of confounding effects poses challenges in achieving an unbiased estimate of the uplift effect. We introduce a consumer subsidizing system to capture relationships between subsidy propensity and the treatment effect, which proves effective while maintaining a lightweight online environment.
A Data-driven Region Generation Framework for Spatiotemporal Transportation Service Management
Jun 05, 2023MAUP (modifiable areal unit problem) is a fundamental problem for spatial data management and analysis. As an instantiation of MAUP in online transportation platforms, region generation (i.e., specifying the areal unit for service operations) is the first and vital step for supporting spatiotemporal transportation services such as ride-sharing and freight transport. Most existing region generation methods are manually specified (e.g., fixed-size grids), suffering from poor spatial semantic meaning and inflexibility to meet service operation requirements. In this paper, we propose RegionGen, a data-driven region generation framework that can specify regions with key characteristics (e.g., good spatial semantic meaning and predictability) by modeling region generation as a multi-objective optimization problem. First, to obtain good spatial semantic meaning, RegionGen segments the whole city into atomic spatial elements based on road networks and obstacles (e.g., rivers). Then, it clusters the atomic spatial elements into regions by maximizing various operation characteristics, which is formulated as a multi-objective optimization problem. For this optimization problem, we propose a multi-objective co-optimization algorithm. Extensive experiments verify that RegionGen can generate more suitable regions than traditional methods for spatiotemporal service management.
An Argumentation-Based Legal Reasoning Approach for DL-Ontology
Sep 18, 2022

Ontology is a popular method for knowledge representation in different domains, including the legal domain, and description logics (DL) is commonly used as its description language. To handle reasoning based on inconsistent DL-based legal ontologies, the current paper presents a structured argumentation framework particularly for reasoning in legal contexts on the basis of ASPIC+, and translates the legal ontology into formulas and rules of an argumentation theory. With a particular focus on the design of autonomous vehicles from the perspective of legal AI, we show that using this combined theory of formal argumentation and DL-based legal ontology, acceptable assertions can be obtained based on inconsistent ontologies, and the traditional reasoning tasks of DL ontologies can also be accomplished. In addition, a formal definition of explanations for the result of reasoning is presented.