 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Separation: Evaluating Separation on Comparative Judgment Test Data
Jan 11, 2026This research seeks to benefit the software engineering society by proposing comparative separation, a novel group fairness notion to evaluate the fairness of machine learning software on comparative judgment test data. Fairness issues have attracted increasing attention since machine learning software is increasingly used for high-stakes and high-risk decisions. It is the responsibility of all software developers to make their software accountable by ensuring that the machine learning software do not perform differently on different sensitive groups -- satisfying the separation criterion. However, evaluation of separation requires ground truth labels for each test data point. This motivates our work on analyzing whether separation can be evaluated on comparative judgment test data. Instead of asking humans to provide the ratings or categorical labels on each test data point, comparative judgments are made between pairs of data points such as A is better than B. According to the law of comparative judgment, providing such comparative judgments yields a lower cognitive burden for humans than providing ratings or categorical labels. This work first defines the novel fairness notion comparative separation on comparative judgment test data, and the metrics to evaluate comparative separation. Then, both theoretically and empirically, we show that in binary classification problems, comparative separation is equivalent to separation. Lastly, we analyze the number of test data points and test data pairs required to achieve the same level of statistical power in the evaluation of separation and comparative separation, respectively. This work is the first to explore fairness evaluation on comparative judgment test data. It shows the feasibility and the practical benefits of using comparative judgment test data for model evaluations.
FairReweighing: Density Estimation-Based Reweighing Framework for Improving Separation in Fair Regression
Nov 14, 2025There has been a prevalence of applying AI software in both high-stakes public-sector and industrial contexts. However, the lack of transparency has raised concerns about whether these data-informed AI software decisions secure fairness against people of all racial, gender, or age groups. Despite extensive research on emerging fairness-aware AI software, up to now most efforts to solve this issue have been dedicated to binary classification tasks. Fairness in regression is relatively underexplored. In this work, we adopted a mutual information-based metric to assess separation violations. The metric is also extended so that it can be directly applied to both classification and regression problems with both binary and continuous sensitive attributes. Inspired by the Reweighing algorithm in fair classification, we proposed a FairReweighing pre-processing algorithm based on density estimation to ensure that the learned model satisfies the separation criterion. Theoretically, we show that the proposed FairReweighing algorithm can guarantee separation in the training data under a data independence assumption. Empirically, on both synthetic and real-world data, we show that FairReweighing outperforms existing state-of-the-art regression fairness solutions in terms of improving separation while maintaining high accuracy.
A Pilot Study on Detecting Unfairness in Human Decisions With Machine Learning Algorithmic Bias Detection
Dec 21, 2021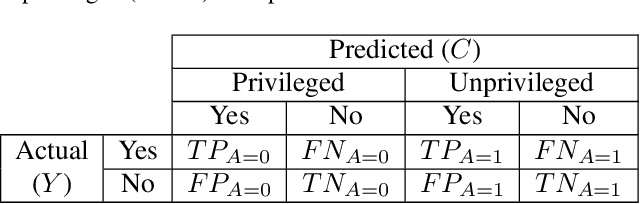


Fairness in decision-making has been a long-standing issue in our society. Despite the increasing number of research activities on unfairness mitigation in machine learning models, there is little research focusing on mitigating unfairness in human decisions. Fairness in human decisions is as important as, if not more important than, fairness in machine learning models since there are processes where humans make the final decisions and machine learning models can inherit bias from the human decisions they were trained on. As a result, this work aims to detect unfairness in human decisions, the very first step of solving the unfair human decision problem. This paper proposes to utilize the existing machine learning fairness detection mechanisms to detect unfairness in human decisions. The rationale behind this is, while it is difficult to directly test whether a human makes unfair decisions, with current research on machine learning fairness, it is now easy to test, on a large scale at a low cost, whether a machine learning model is unfair. By synthesizing unfair labels on four general machine learning fairness datasets and one image processing dataset, this paper shows that the proposed approach is able to detect (1) whether or not unfair labels exist in the training data and (2) the degree and direction of the unfairness. We believe that this work demonstrates the potential of utilizing machine learning fairness to detect human decision fairness. Following this work, research can be conducted on (1) preventing future unfair decisions, (2) fixing prior unfair decisions, and (3) training a fairer machine learning model.