 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfounding Tradeoffs for Neural Network Quantization
Feb 12, 2021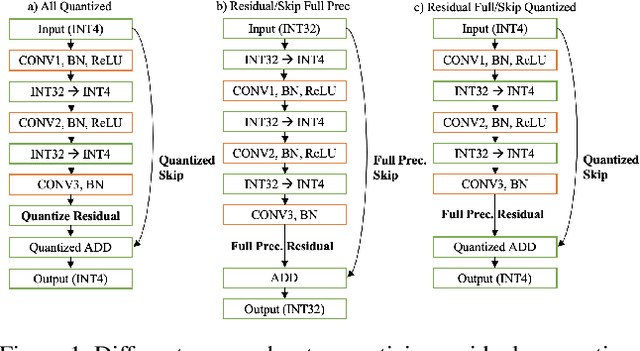

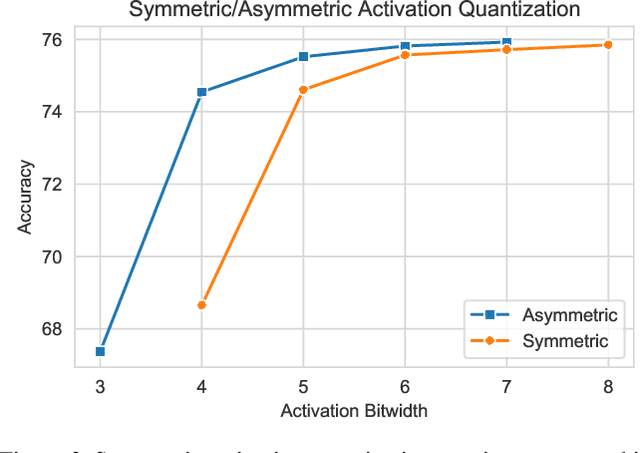
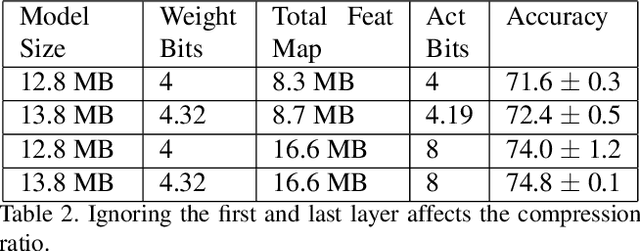
Many neural network quantization techniques have been developed to decrease the computational and memory footprint of deep learning. However, these methods are evaluated subject to confounding tradeoffs that may affect inference acceleration or resource complexity in exchange for higher accuracy. In this work, we articulate a variety of tradeoffs whose impact is often overlooked and empirically analyze their impact on uniform and mixed-precision post-training quantization, finding that these confounding tradeoffs may have a larger impact on quantized network accuracy than the actual quantization methods themselves. Because these tradeoffs constrain the attainable hardware acceleration for different use-cases, we encourage researchers to explicitly report these design choices through the structure of "quantization cards." We expect quantization cards to help researchers compare methods more effectively and engineers determine the applicability of quantization techniques for their hardware.
Dynamic Precision Analog Computing for Neural Networks
Feb 12, 2021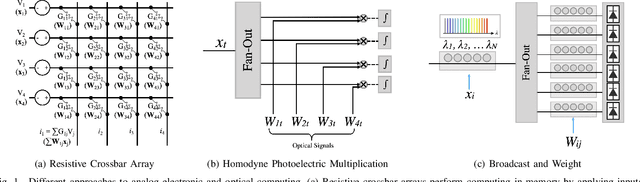

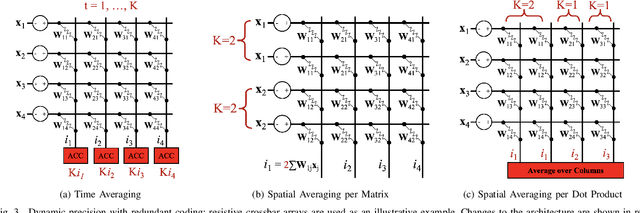
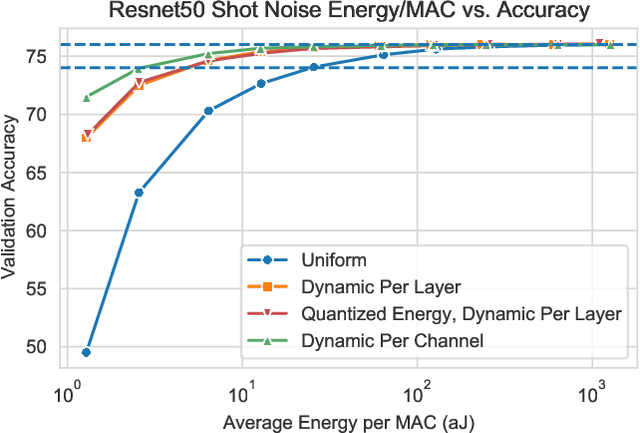
Analog electronic and optical computing exhibit tremendous advantages over digital computing for accelerating deep learning when operations are executed at low precision. In this work, we derive a relationship between analog precision, which is limited by noise, and digital bit precision. We propose extending analog computing architectures to support varying levels of precision by repeating operations and averaging the result, decreasing the impact of noise. Such architectures enable programmable tradeoffs between precision and other desirable performance metrics such as energy efficiency or throughput. To utilize dynamic precision, we propose a method for learning the precision of each layer of a pre-trained model without retraining network weights. We evaluate this method on analog architectures subject to a variety of noise sources such as shot noise, thermal noise, and weight noise and find that employing dynamic precision reduces energy consumption by up to 89% for computer vision models such as Resnet50 and by 24% for natural language processing models such as BERT. In one example, we apply dynamic precision to a shot-noise limited homodyne optical neural network and simulate inference at an optical energy consumption of 2.7 aJ/MAC for Resnet50 and 1.6 aJ/MAC for BERT with <2% accuracy degradation.