 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Fairness in Text Classification through Robustness
Paper and Code
Sep 27, 2018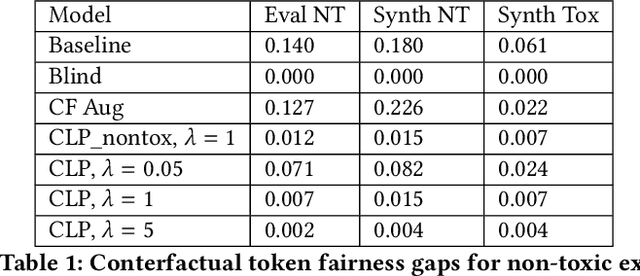
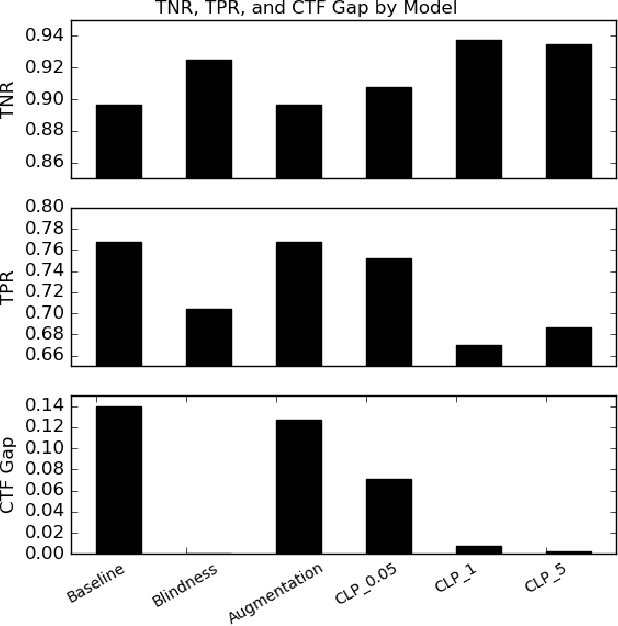
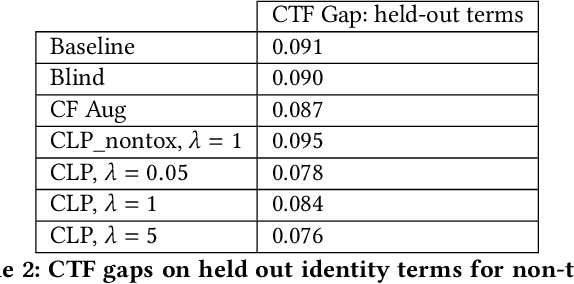
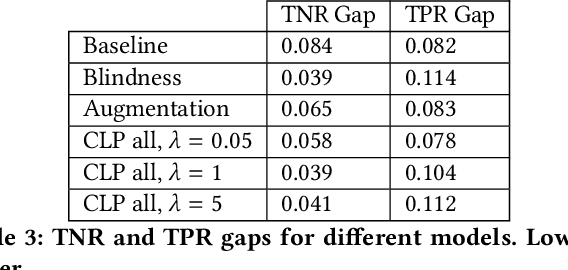
In this paper, we study counterfactual fairness in text classification, which asks the question: How would the prediction change if the sensitive attribute discussed in the example were something else? We offer a heuristic for measuring this particular form of fairness in text classifiers by substituting individual tokens pertaining to attributes (e.g. sexual orientation, race, and religion), and describe the relationship with other notions, including individual and group fairness. Further, we offer methods, including hard ablation, blindness, and counterfactual logit pairing, for optimizing this counterfactual fairness metric during model training, bridging the robustness literature and the fairness literature. Empirically, counterfactual logit pairing performs as well as hard ablation and blindness to sensitive tokens, but generalizes better to unseen tokens. Interestingly, we find that in practice, the methods do not significantly harm classifier performance, and have varying tradeoffs with group fairness. These approaches, both for measurement and optimization, provide a new path forward for addressing counterfactual fairness issues.