 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Bias Measures Measure?
Aug 07, 2021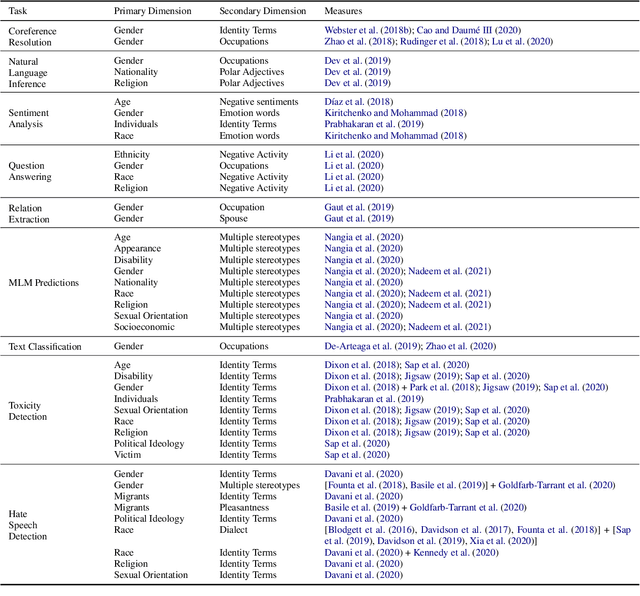
Natural Language Processing (NLP) models propagate social biases about protected attributes such as gender, race, and nationality. To create interventions and mitigate these biases and associated harms, it is vital to be able to detect and measure such biases. While many existing works propose bias evaluation methodologies for different tasks, there remains a need to cohesively understand what biases and normative harms each of these measures captures and how different measures compare. To address this gap, this work presents a comprehensive survey of existing bias measures in NLP as a function of the associated NLP tasks, metrics, datasets, and social biases and corresponding harms. This survey also organizes metrics into different categories to present advantages and disadvantages. Finally, we propose a documentation standard for bias measures to aid their development, categorization, and appropriate usage.