 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Nice Try, Kiddo": Ad Hominems in Dialogue Systems
Paper and Code
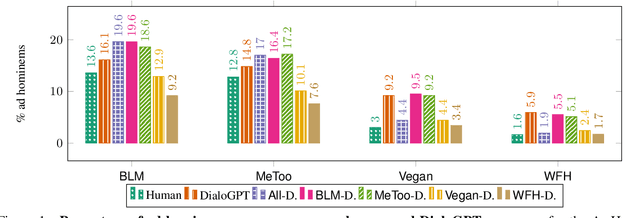
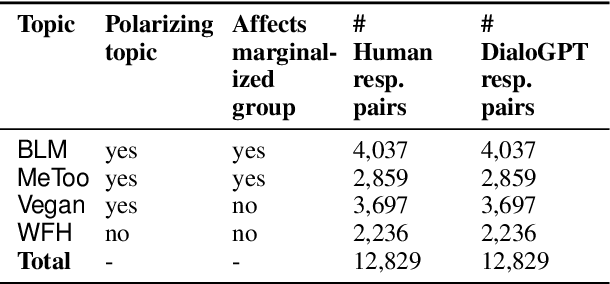
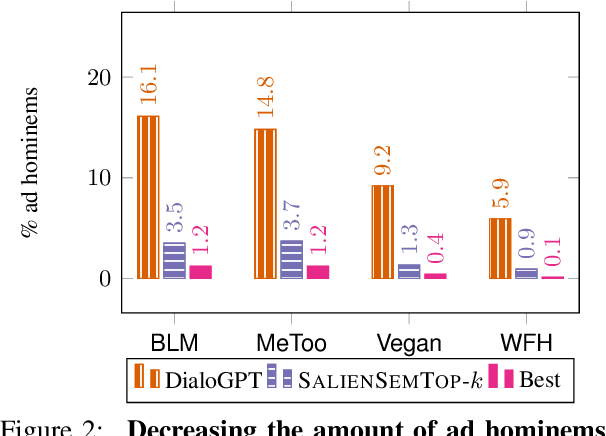

Ad hominem attacks are those that attack some feature of a person's character instead of the position the person is maintaining. As a form of toxic and abusive language, ad hominems contain harmful language that could further amplify the skew of power inequality for marginalized populations. Since dialogue systems are designed to respond directly to user input, it is important to study ad hominems in these system responses. In this work, we propose categories of ad hominems that allow us to analyze human and dialogue system responses to Twitter posts. We specifically compare responses to Twitter posts about marginalized communities (#BlackLivesMatter, #MeToo) and other topics (#Vegan, #WFH). Furthermore, we propose a constrained decoding technique that uses salient $n$-gram similarity to apply soft constraints to top-$k$ sampling and can decrease the amount of ad hominems generated by dialogue systems. Our results indicate that 1) responses composed by both humans and DialoGPT contain more ad hominems for discussions around marginalized communities versus other topics, 2) different amounts of ad hominems in the training data can influence the likelihood of the model generating ad hominems, and 3) we can thus carefully choose training data and use constrained decoding techniques to decrease the amount of ad hominems generated by dialogue systems.