 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend to the beginning: A study on using bidirectional attention for extractive summarization
Paper and Code
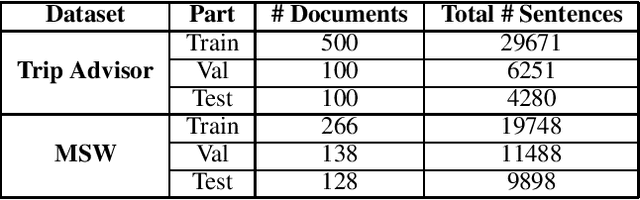
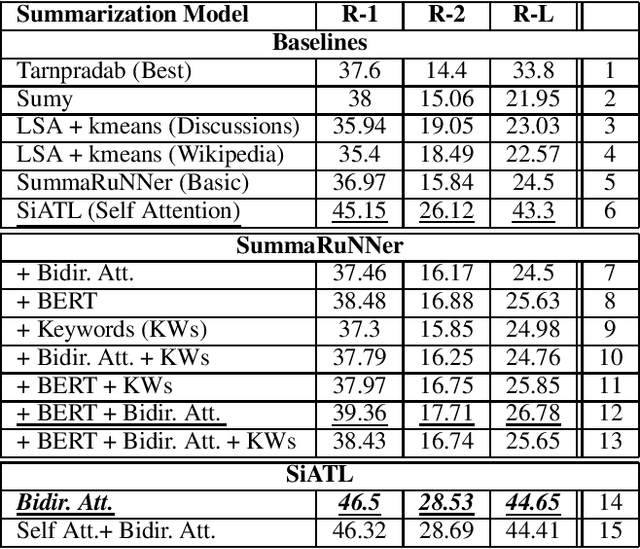


Forum discussion data differ in both structure and properties from generic form of textual data such as news. Henceforth, summarization techniques should, in turn, make use of such differences, and craft models that can benefit from the structural nature of discussion data. In this work, we propose attending to the beginning of a document, to improve the performance of extractive summarization models when applied to forum discussion data. Evaluations demonstrated that with the help of bidirectional attention mechanism, attending to the beginning of a document (initial comment/post) in a discussion thread, can introduce a consistent boost in ROUGE scores, as well as introducing a new State Of The Art (SOTA) ROUGE scores on the forum discussions dataset. Additionally, we explored whether this hypothesis is extendable to other generic forms of textual data. We make use of the tendency of introducing important information early in the text, by attending to the first few sentences in generic textual data. Evaluations demonstrated that attending to introductory sentences using bidirectional attention, improves the performance of extractive summarization models when even applied to more generic form of textual data.