 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Benchmark of Histopathology Foundation Models for Kidney Histopathology
Mar 16, 2026Histopathology foundation models (HFMs), pretrained on large-scale cancer datasets, have advanced computational pathology. However, their applicability to non-cancerous chronic kidney disease remains underexplored, despite coexistence of renal pathology with malignancies such as renal cell and urothelial carcinoma. We systematically evaluate 11 publicly available HFMs across 11 kidney-specific downstream tasks spanning multiple stains (PAS, H&E, PASM, and IHC), spatial scales (tile and slide-level), task types (classification, regression, and copy detection), and clinical objectives, including detection, diagnosis, and prognosis. Tile-level performance is assessed using repeated stratified group cross-validation, while slide-level tasks are evaluated using repeated nested stratified cross-validation. Statistical significance is examined using Friedman test followed by pairwise Wilcoxon signed-rank testing with Holm-Bonferroni correction and compact letter display visualization. To promote reproducibility, we release an open-source Python package, kidney-hfm-eval, available at https://pypi.org/project/kidney-hfm-eval/ , that reproduces the evaluation pipelines. Results show moderate to strong performance on tasks driven by coarse meso-scale renal morphology, including diagnostic classification and detection of prominent structural alterations. In contrast, performance consistently declines for tasks requiring fine-grained microstructural discrimination, complex biological phenotypes, or slide-level prognostic inference, largely independent of stain type. Overall, current HFMs appear to encode predominantly static meso-scale representations and may have limited capacity to capture subtle renal pathology or prognosis-related signals. Our results highlight the need for kidney-specific, multi-stain, and multimodal foundation models to support clinically reliable decision-making in nephrology.
Extending $μ$P: Spectral Conditions for Feature Learning Across Optimizers
Feb 24, 2026Several variations of adaptive first-order and second-order optimization methods have been proposed to accelerate and scale the training of large language models. The performance of these optimization routines is highly sensitive to the choice of hyperparameters (HPs), which are computationally expensive to tune for large-scale models. Maximal update parameterization $(μ$P$)$ is a set of scaling rules which aims to make the optimal HPs independent of the model size, thereby allowing the HPs tuned on a smaller (computationally cheaper) model to be transferred to train a larger, target model. Despite promising results for SGD and Adam, deriving $μ$P for other optimizers is challenging because the underlying tensor programming approach is difficult to grasp. Building on recent work that introduced spectral conditions as an alternative to tensor programs, we propose a novel framework to derive $μ$P for a broader class of optimizers, including AdamW, ADOPT, LAMB, Sophia, Shampoo and Muon. We implement our $μ$P derivations on multiple benchmark models and demonstrate zero-shot learning rate transfer across increasing model width for the above optimizers. Further, we provide empirical insights into depth-scaling parameterization for these optimizers.
Information-Driven Fault Detection and Identification for Multi-Agent Spacecraft Systems: Collaborative On-Orbit Inspection Mission
Nov 11, 2025This work presents a global-to-local, task-aware fault detection and identification (FDI) framework for multi-spacecraft systems conducting collaborative inspection missions in low Earth orbit. The inspection task is represented by a global information-driven cost functional that integrates the sensor model, spacecraft poses, and mission-level information-gain objectives. This formulation links guidance, control, and FDI by using the same cost function to drive both global task allocation and local sensing or motion decisions. Fault detection is achieved through comparisons between expected and observed task metrics, while higher-order cost-gradient measures enable the identification of faults among sensors, actuators, and state estimators. An adaptive thresholding mechanism captures the time-varying inspection geometry and dynamic mission conditions. Simulation results for representative multi-spacecraft inspection scenarios demonstrate the reliability of fault localization and classification under uncertainty, providing a unified, information-driven foundation for resilient autonomous inspection architectures.
A multi-modal dataset for insect biodiversity with imagery and DNA at the trap and individual level
Jul 09, 2025Insects comprise millions of species, many experiencing severe population declines under environmental and habitat changes. High-throughput approaches are crucial for accelerating our understanding of insect diversity, with DNA barcoding and high-resolution imaging showing strong potential for automatic taxonomic classification. However, most image-based approaches rely on individual specimen data, unlike the unsorted bulk samples collected in large-scale ecological surveys. We present the Mixed Arthropod Sample Segmentation and Identification (MassID45) dataset for training automatic classifiers of bulk insect samples. It uniquely combines molecular and imaging data at both the unsorted sample level and the full set of individual specimens. Human annotators, supported by an AI-assisted tool, performed two tasks on bulk images: creating segmentation masks around each individual arthropod and assigning taxonomic labels to over 17 000 specimens. Combining the taxonomic resolution of DNA barcodes with precise abundance estimates of bulk images holds great potential for rapid, large-scale characterization of insect communities. This dataset pushes the boundaries of tiny object detection and instance segmentation, fostering innovation in both ecological and machine learning research.
Global Task-aware Fault Detection, Identification For On-Orbit Multi-Spacecraft Collaborative Inspection
May 06, 2025In this paper, we present a global-to-local task-aware fault detection and identification algorithm to detect failures in a multi-spacecraft system performing a collaborative inspection (referred to as global) task. The inspection task is encoded as a cost functional $\costH$ that informs global (task allocation and assignment) and local (agent-level) decision-making. The metric $\costH$ is a function of the inspection sensor model, and the agent full-pose. We use the cost functional $\costH$ to design a metric that compares the expected and actual performance to detect the faulty agent using a threshold. We use higher-order cost gradients $\costH$ to derive a new metric to identify the type of fault, including task-specific sensor fault, an agent-level actuator, and sensor faults. Furthermore, we propose an approach to design adaptive thresholds for each fault mentioned above to incorporate the time dependence of the inspection task. We demonstrate the efficacy of the proposed method empirically, by simulating and detecting faults (such as inspection sensor faults, actuators, and sensor faults) in a low-Earth orbit collaborative spacecraft inspection task using the metrics and the threshold designed using the global task cost $\costH$.
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
Nov 26, 2024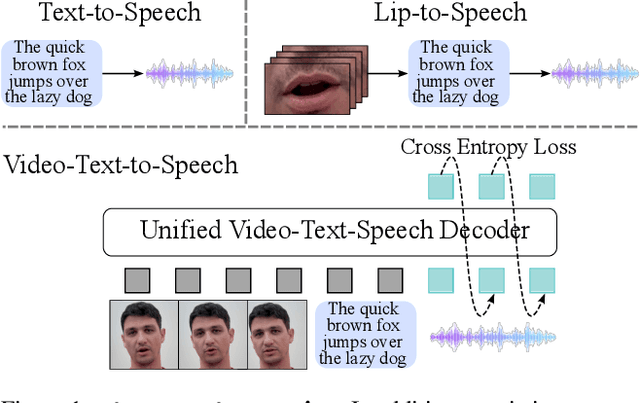



In this paper, we propose a new task -- generating speech from videos of people and their transcripts (VTTS) -- to motivate new techniques for multimodal speech generation. This task generalizes the task of generating speech from cropped lip videos, and is also more complicated than the task of generating generic audio clips (e.g., dog barking) from videos and text. Multilingual versions of the task could lead to new techniques for cross-lingual dubbing. We also present a decoder-only multimodal model for this task, which we call Visatronic. This model embeds vision, text and speech directly into the common subspace of a transformer model and uses an autoregressive loss to learn a generative model of discretized mel-spectrograms conditioned on speaker videos and transcripts of their speech. By embedding all modalities into a common subspace, Visatronic can achieve improved results over models that use only text or video as input. Further, it presents a much simpler approach for multimodal speech generation compared to prevailing approaches which rely on lip-detectors and complicated architectures to fuse modalities while producing better results. Since the model is flexible enough to accommodate different ways of ordering inputs as a sequence, we carefully explore different strategies to better understand the best way to propagate information to the generative steps. To facilitate further research on VTTS, we will release (i) our code, (ii) clean transcriptions for the large-scale VoxCeleb2 dataset, and (iii) a standardized evaluation protocol for VTTS incorporating both objective and subjective metrics.
Open-Vocabulary Temporal Action Localization using Multimodal Guidance
Jun 21, 2024Open-Vocabulary Temporal Action Localization (OVTAL) enables a model to recognize any desired action category in videos without the need to explicitly curate training data for all categories. However, this flexibility poses significant challenges, as the model must recognize not only the action categories seen during training but also novel categories specified at inference. Unlike standard temporal action localization, where training and test categories are predetermined, OVTAL requires understanding contextual cues that reveal the semantics of novel categories. To address these challenges, we introduce OVFormer, a novel open-vocabulary framework extending ActionFormer with three key contributions. First, we employ task-specific prompts as input to a large language model to obtain rich class-specific descriptions for action categories. Second, we introduce a cross-attention mechanism to learn the alignment between class representations and frame-level video features, facilitating the multimodal guided features. Third, we propose a two-stage training strategy which includes training with a larger vocabulary dataset and finetuning to downstream data to generalize to novel categories. OVFormer extends existing TAL methods to open-vocabulary settings. Comprehensive evaluations on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our method. Code and pretrained models will be publicly released.
LoSA: Long-Short-range Adapter for Scaling End-to-End Temporal Action Localization
Apr 01, 2024



Temporal Action Localization (TAL) involves localizing and classifying action snippets in an untrimmed video. The emergence of large video foundation models has led RGB-only video backbones to outperform previous methods needing both RGB and optical flow modalities. Leveraging these large models is often limited to training only the TAL head due to the prohibitively large GPU memory required to adapt the video backbone for TAL. To overcome this limitation, we introduce LoSA, the first memory-and-parameter-efficient backbone adapter designed specifically for TAL to handle untrimmed videos. LoSA specializes for TAL by introducing Long-Short-range Adapters that adapt the intermediate layers of the video backbone over different temporal ranges. These adapters run parallel to the video backbone to significantly reduce memory footprint. LoSA also includes Long-Short-range Fusion that strategically combines the output of these adapters from the video backbone layers to enhance the video features provided to the TAL head. Experiments show that LoSA significantly outperforms all existing methods on standard TAL benchmarks, THUMOS-14 and ActivityNet-v1.3, by scaling end-to-end backbone adaptation to billion-parameter-plus models like VideoMAEv2~(ViT-g) and leveraging them beyond head-only transfer learning.
Multimodality in Online Education: A Comparative Study
Dec 17, 2023



The commencement of the decade brought along with it a grave pandemic and in response the movement of education forums predominantly into the online world. With a surge in the usage of online video conferencing platforms and tools to better gauge student understanding, there needs to be a mechanism to assess whether instructors can grasp the extent to which students understand the subject and their response to the educational stimuli. The current systems consider only a single cue with a lack of focus in the educational domain. Thus, there is a necessity for the measurement of an all-encompassing holistic overview of the students' reaction to the subject matter. This paper highlights the need for a multimodal approach to affect recognition and its deployment in the online classroom while considering four cues, posture and gesture, facial, eye tracking and verbal recognition. It compares the various machine learning models available for each cue and provides the most suitable approach given the available dataset and parameters of classroom footage. A multimodal approach derived from weighted majority voting is proposed by combining the most fitting models from this analysis of individual cues based on accuracy, ease of procuring data corpus, sensitivity and any major drawbacks.
OW-DETR: Open-world Detection Transformer
Dec 09, 2021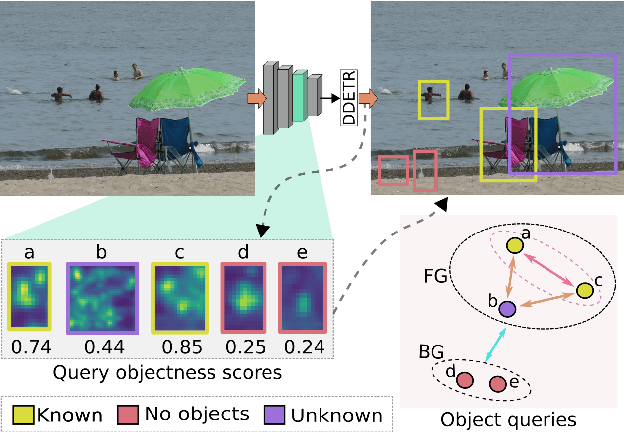
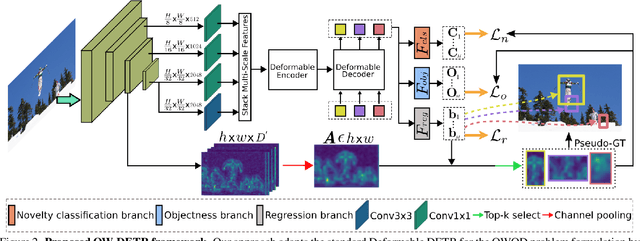
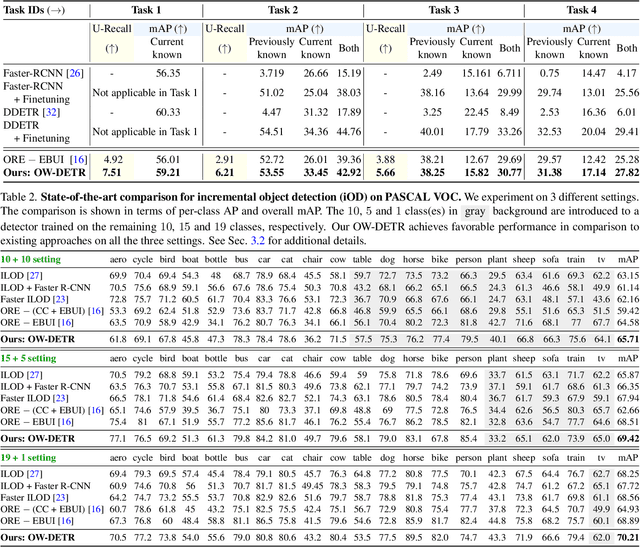
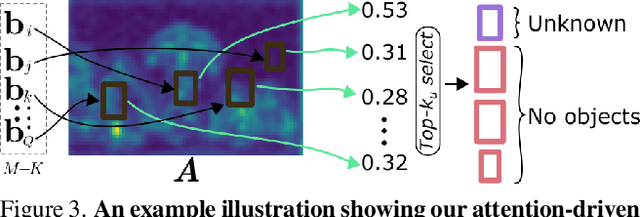
Open-world object detection (OWOD) is a challenging computer vision problem, where the task is to detect a known set of object categories while simultaneously identifying unknown objects. Additionally, the model must incrementally learn new classes that become known in the next training episodes. Distinct from standard object detection, the OWOD setting poses significant challenges for generating quality candidate proposals on potentially unknown objects, separating the unknown objects from the background and detecting diverse unknown objects. Here, we introduce a novel end-to-end transformer-based framework, OW-DETR, for open-world object detection. The proposed OW-DETR comprises three dedicated components namely, attention-driven pseudo-labeling, novelty classification and objectness scoring to explicitly address the aforementioned OWOD challenges. Our OW-DETR explicitly encodes multi-scale contextual information, possesses less inductive bias, enables knowledge transfer from known classes to the unknown class and can better discriminate between unknown objects and background. Comprehensive experiments are performed on two benchmarks: MS-COCO and PASCAL VOC. The extensive ablations reveal the merits of our proposed contributions. Further, our model outperforms the recently introduced OWOD approach, ORE, with absolute gains ranging from 1.8% to 3.3% in terms of unknown recall on the MS-COCO benchmark. In the case of incremental object detection, OW-DETR outperforms the state-of-the-art for all settings on the PASCAL VOC benchmark. Our codes and models will be publicly released.