 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakStream: Streaming Text-to-Speech with Interleaved Data
May 25, 2025The latency bottleneck of traditional text-to-speech (TTS) systems fundamentally hinders the potential of streaming large language models (LLMs) in conversational AI. These TTS systems, typically trained and inferenced on complete utterances, introduce unacceptable delays, even with optimized inference speeds, when coupled with streaming LLM outputs. This is particularly problematic for creating responsive conversational agents where low first-token latency is critical. In this paper, we present SpeakStream, a streaming TTS system that generates audio incrementally from streaming text using a decoder-only architecture. SpeakStream is trained using a next-step prediction loss on interleaved text-speech data. During inference, it generates speech incrementally while absorbing streaming input text, making it particularly suitable for cascaded conversational AI agents where an LLM streams text to a TTS system. Our experiments demonstrate that SpeakStream achieves state-of-the-art latency results in terms of first-token latency while maintaining the quality of non-streaming TTS systems.
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
Nov 26, 2024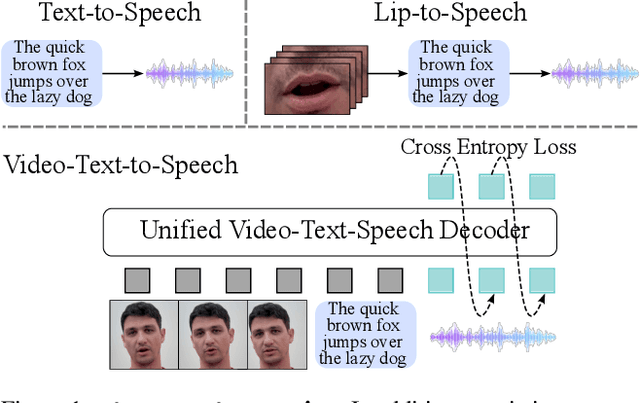



In this paper, we propose a new task -- generating speech from videos of people and their transcripts (VTTS) -- to motivate new techniques for multimodal speech generation. This task generalizes the task of generating speech from cropped lip videos, and is also more complicated than the task of generating generic audio clips (e.g., dog barking) from videos and text. Multilingual versions of the task could lead to new techniques for cross-lingual dubbing. We also present a decoder-only multimodal model for this task, which we call Visatronic. This model embeds vision, text and speech directly into the common subspace of a transformer model and uses an autoregressive loss to learn a generative model of discretized mel-spectrograms conditioned on speaker videos and transcripts of their speech. By embedding all modalities into a common subspace, Visatronic can achieve improved results over models that use only text or video as input. Further, it presents a much simpler approach for multimodal speech generation compared to prevailing approaches which rely on lip-detectors and complicated architectures to fuse modalities while producing better results. Since the model is flexible enough to accommodate different ways of ordering inputs as a sequence, we carefully explore different strategies to better understand the best way to propagate information to the generative steps. To facilitate further research on VTTS, we will release (i) our code, (ii) clean transcriptions for the large-scale VoxCeleb2 dataset, and (iii) a standardized evaluation protocol for VTTS incorporating both objective and subjective metrics.