 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrassmannian learning mutual subspace method for image set recognition
Paper and Code
Nov 08, 2021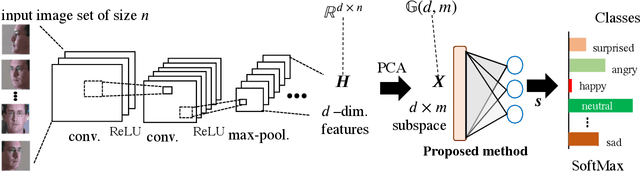
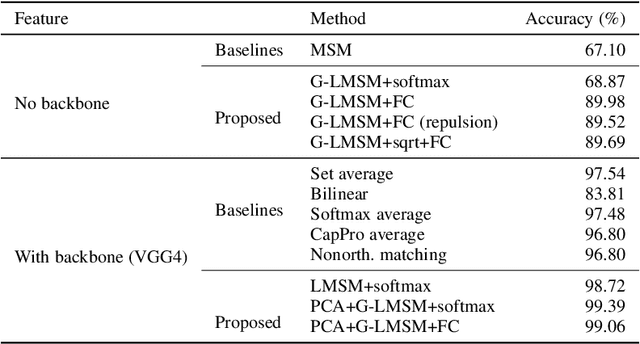
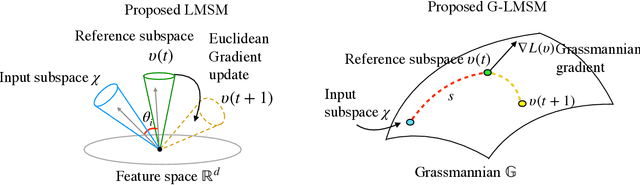
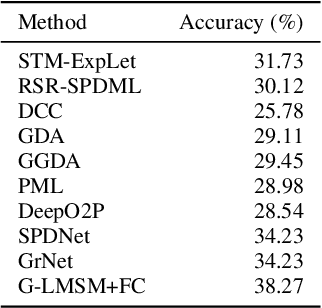
This paper addresses the problem of object recognition given a set of images as input (e.g., multiple camera sources and video frames). Convolutional neural network (CNN)-based frameworks do not exploit these sets effectively, processing a pattern as observed, not capturing the underlying feature distribution as it does not consider the variance of images in the set. To address this issue, we propose the Grassmannian learning mutual subspace method (G-LMSM), a NN layer embedded on top of CNNs as a classifier, that can process image sets more effectively and can be trained in an end-to-end manner. The image set is represented by a low-dimensional input subspace; and this input subspace is matched with reference subspaces by a similarity of their canonical angles, an interpretable and easy to compute metric. The key idea of G-LMSM is that the reference subspaces are learned as points on the Grassmann manifold, optimized with Riemannian stochastic gradient descent. This learning is stable, efficient and theoretically well-grounded. We demonstrate the effectiveness of our proposed method on hand shape recognition, face identification, and facial emotion recognition.