 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rotation in Self-Supervised Contrastive Learning: Adaptive Positive or Negative Data Augmentation
Oct 23, 2022Rotation is frequently listed as a candidate for data augmentation in contrastive learning but seldom provides satisfactory improvements. We argue that this is because the rotated image is always treated as either positive or negative. The semantics of an image can be rotation-invariant or rotation-variant, so whether the rotated image is treated as positive or negative should be determined based on the content of the image. Therefore, we propose a novel augmentation strategy, adaptive Positive or Negative Data Augmentation (PNDA), in which an original and its rotated image are a positive pair if they are semantically close and a negative pair if they are semantically different. To achieve PNDA, we first determine whether rotation is positive or negative on an image-by-image basis in an unsupervised way. Then, we apply PNDA to contrastive learning frameworks. Our experiments showed that PNDA improves the performance of contrastive learning. The code is available at \url{ https://github.com/AtsuMiyai/rethinking_rotation}.
Generalized Domain Adaptation
Jun 03, 2021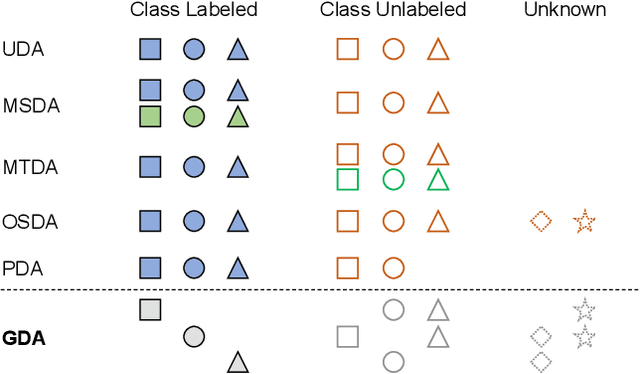

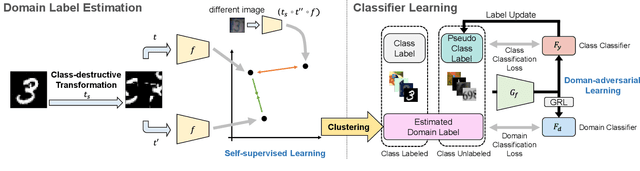
Many variants of unsupervised domain adaptation (UDA) problems have been proposed and solved individually. Its side effect is that a method that works for one variant is often ineffective for or not even applicable to another, which has prevented practical applications. In this paper, we give a general representation of UDA problems, named Generalized Domain Adaptation (GDA). GDA covers the major variants as special cases, which allows us to organize them in a comprehensive framework. Moreover, this generalization leads to a new challenging setting where existing methods fail, such as when domain labels are unknown, and class labels are only partially given to each domain. We propose a novel approach to the new setting. The key to our approach is self-supervised class-destructive learning, which enables the learning of class-invariant representations and domain-adversarial classifiers without using any domain labels. Extensive experiments using three benchmark datasets demonstrate that our method outperforms the state-of-the-art UDA methods in the new setting and that it is competitive in existing UDA variations as well.
A Novel Perspective for Positive-Unlabeled Learning via Noisy Labels
Mar 08, 2021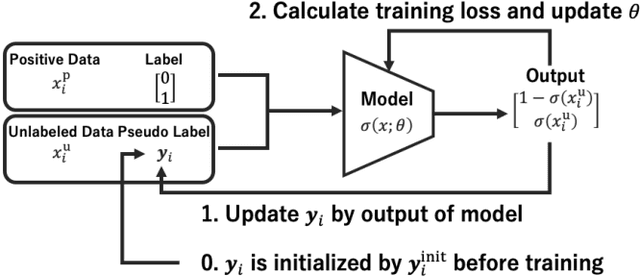
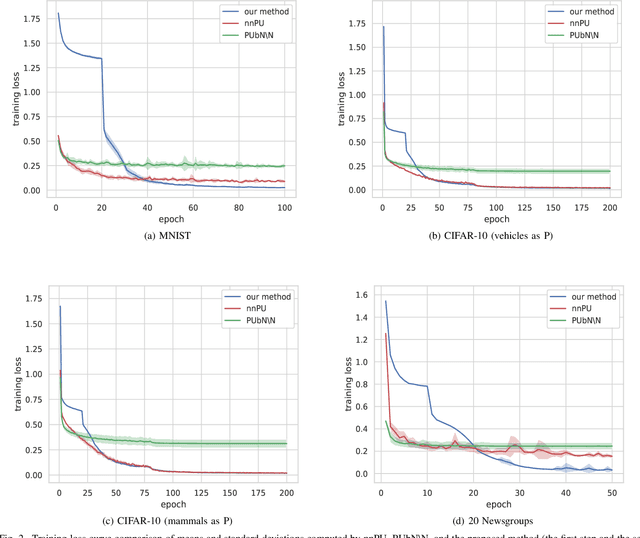
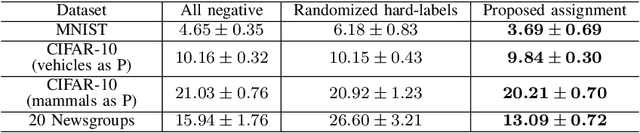
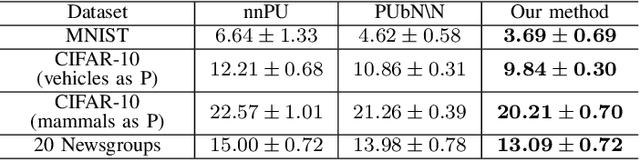
Positive-unlabeled learning refers to the process of training a binary classifier using only positive and unlabeled data. Although unlabeled data can contain positive data, all unlabeled data are regarded as negative data in existing positive-unlabeled learning methods, which resulting in diminishing performance. We provide a new perspective on this problem -- considering unlabeled data as noisy-labeled data, and introducing a new formulation of PU learning as a problem of joint optimization of noisy-labeled data. This research presents a methodology that assigns initial pseudo-labels to unlabeled data which is used as noisy-labeled data, and trains a deep neural network using the noisy-labeled data. Experimental results demonstrate that the proposed method significantly outperforms the state-of-the-art methods on several benchmark datasets.
The Aleatoric Uncertainty Estimation Using a Separate Formulation with Virtual Residuals
Nov 03, 2020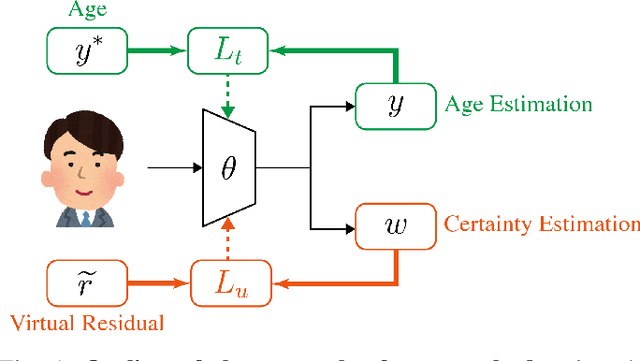
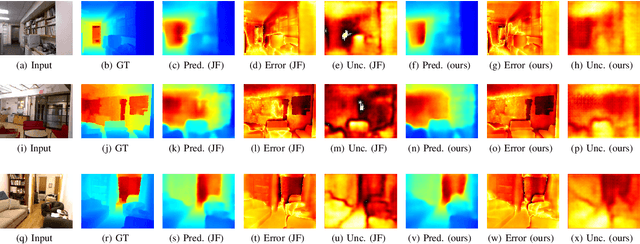
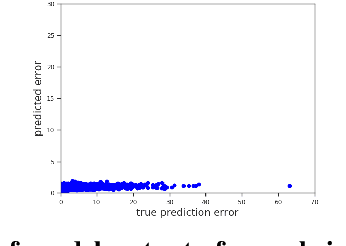
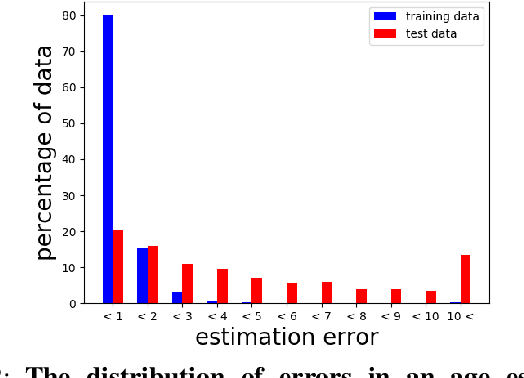
We propose a new optimization framework for aleatoric uncertainty estimation in regression problems. Existing methods can quantify the error in the target estimation, but they tend to underestimate it. To obtain the predictive uncertainty inherent in an observation, we propose a new separable formulation for the estimation of a signal and of its uncertainty, avoiding the effect of overfitting. By decoupling target estimation and uncertainty estimation, we also control the balance between signal estimation and uncertainty estimation. We conduct three types of experiments: regression with simulation data, age estimation, and depth estimation. We demonstrate that the proposed method outperforms a state-of-the-art technique for signal and uncertainty estimation.
Multi-Task Curriculum Framework for Open-Set Semi-Supervised Learning
Jul 22, 2020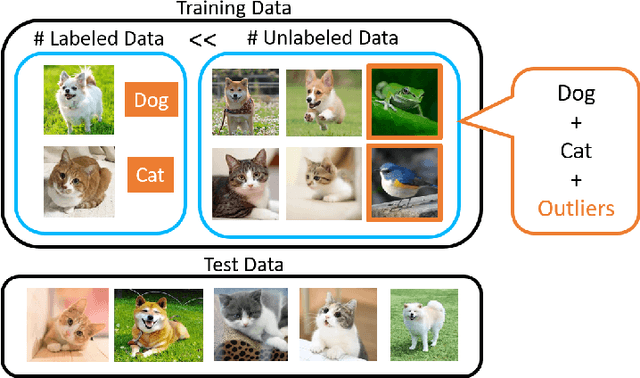
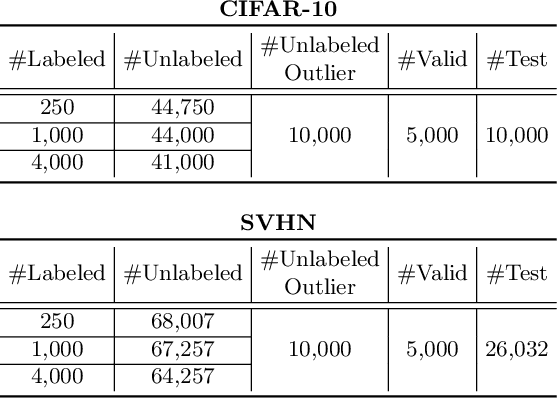
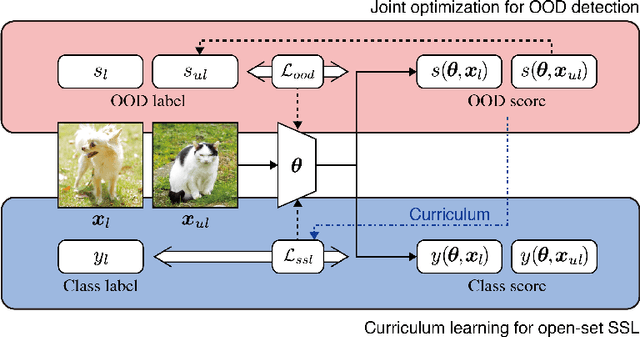
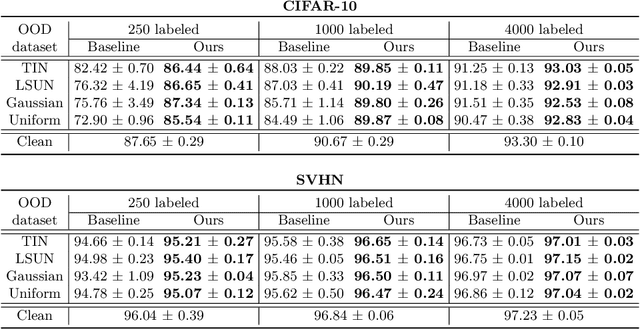
Semi-supervised learning (SSL) has been proposed to leverage unlabeled data for training powerful models when only limited labeled data is available. While existing SSL methods assume that samples in the labeled and unlabeled data share the classes of their samples, we address a more complex novel scenario named open-set SSL, where out-of-distribution (OOD) samples are contained in unlabeled data. Instead of training an OOD detector and SSL separately, we propose a multi-task curriculum learning framework. First, to detect the OOD samples in unlabeled data, we estimate the probability of the sample belonging to OOD. We use a joint optimization framework, which updates the network parameters and the OOD score alternately. Simultaneously, to achieve high performance on the classification of in-distribution (ID) data, we select ID samples in unlabeled data having small OOD scores, and use these data with labeled data for training the deep neural networks to classify ID samples in a semi-supervised manner. We conduct several experiments, and our method achieves state-of-the-art results by successfully eliminating the effect of OOD samples.
Parallel Grid Pooling for Data Augmentation
Mar 30, 2018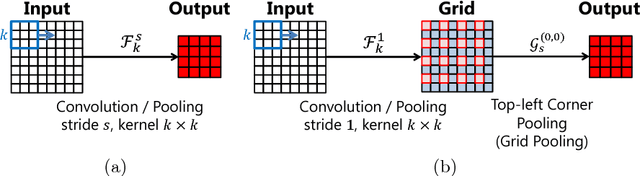
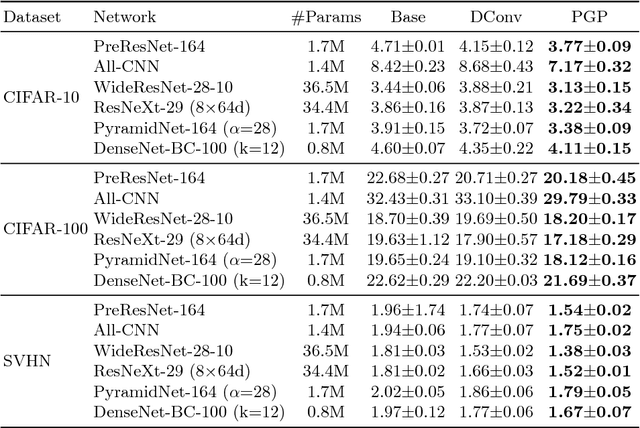
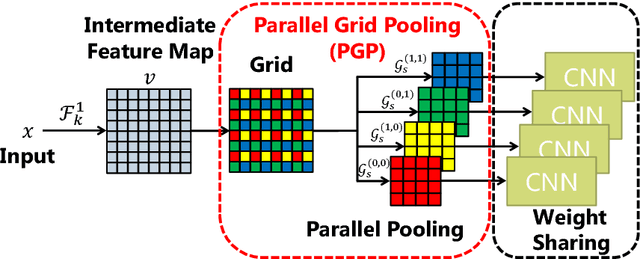
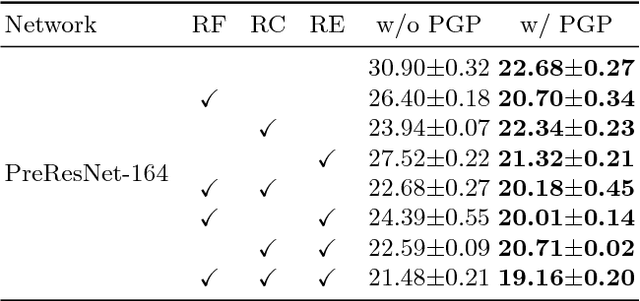
Convolutional neural network (CNN) architectures utilize downsampling layers, which restrict the subsequent layers to learn spatially invariant features while reducing computational costs. However, such a downsampling operation makes it impossible to use the full spectrum of input features. Motivated by this observation, we propose a novel layer called parallel grid pooling (PGP) which is applicable to various CNN models. PGP performs downsampling without discarding any intermediate feature. It works as data augmentation and is complementary to commonly used data augmentation techniques. Furthermore, we demonstrate that a dilated convolution can naturally be represented using PGP operations, which suggests that the dilated convolution can also be regarded as a type of data augmentation technique. Experimental results based on popular image classification benchmarks demonstrate the effectiveness of the proposed method. Code is available at: https://github.com/akitotakeki
Joint Optimization Framework for Learning with Noisy Labels
Mar 30, 2018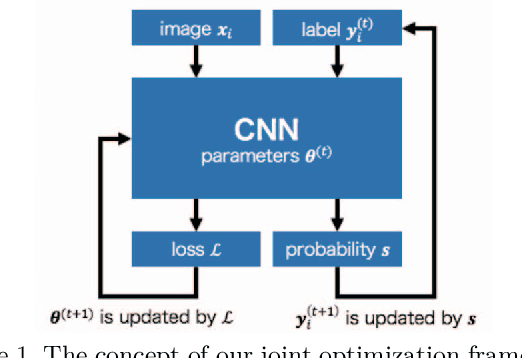

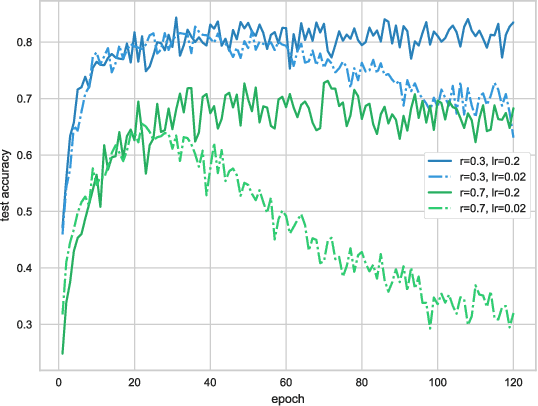
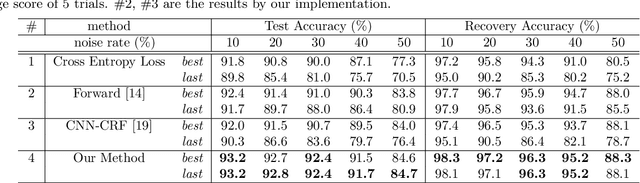
Deep neural networks (DNNs) trained on large-scale datasets have exhibited significant performance in image classification. Many large-scale datasets are collected from websites, however they tend to contain inaccurate labels that are termed as noisy labels. Training on such noisy labeled datasets causes performance degradation because DNNs easily overfit to noisy labels. To overcome this problem, we propose a joint optimization framework of learning DNN parameters and estimating true labels. Our framework can correct labels during training by alternating update of network parameters and labels. We conduct experiments on the noisy CIFAR-10 datasets and the Clothing1M dataset. The results indicate that our approach significantly outperforms other state-of-the-art methods.
Significance of Softmax-based Features in Comparison to Distance Metric Learning-based Features
Dec 29, 2017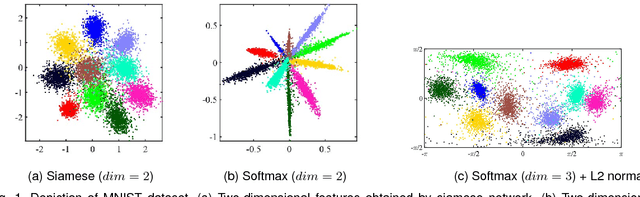
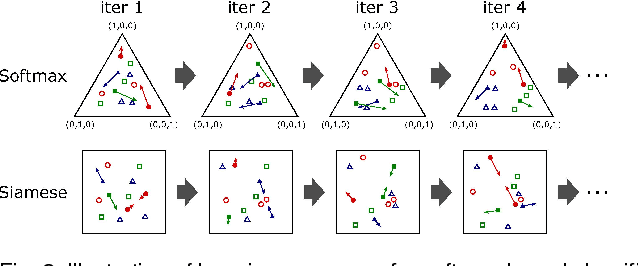
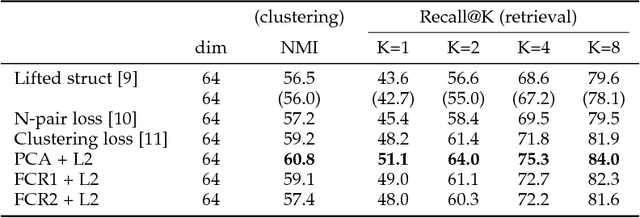
The extraction of useful deep features is important for many computer vision tasks. Deep features extracted from classification networks have proved to perform well in those tasks. To obtain features of greater usefulness, end-to-end distance metric learning (DML) has been applied to train the feature extractor directly. However, in these DML studies, there were no equitable comparisons between features extracted from a DML-based network and those from a softmax-based network. In this paper, by presenting objective comparisons between these two approaches under the same network architecture, we show that the softmax-based features perform competitive, or even better, to the state-of-the-art DML features when the size of the dataset, that is, the number of training samples per class, is large. The results suggest that softmax-based features should be properly taken into account when evaluating the performance of deep features.
Residual Expansion Algorithm: Fast and Effective Optimization for Nonconvex Least Squares Problems
May 26, 2017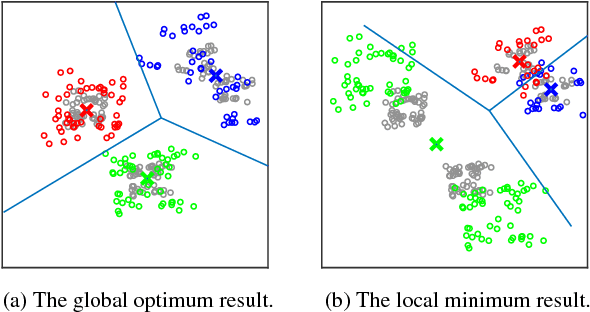

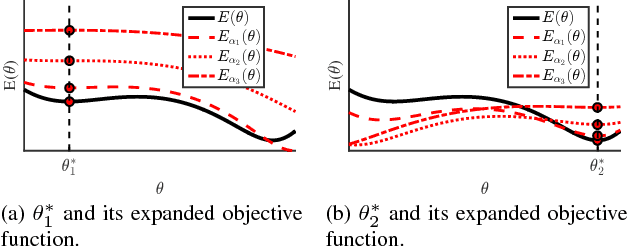
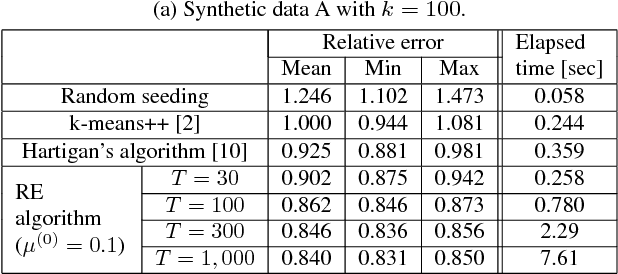
We propose the residual expansion (RE) algorithm: a global (or near-global) optimization method for nonconvex least squares problems. Unlike most existing nonconvex optimization techniques, the RE algorithm is not based on either stochastic or multi-point searches; therefore, it can achieve fast global optimization. Moreover, the RE algorithm is easy to implement and successful in high-dimensional optimization. The RE algorithm exhibits excellent empirical performance in terms of k-means clustering, point-set registration, optimized product quantization, and blind image deblurring.