 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignificance of Softmax-based Features in Comparison to Distance Metric Learning-based Features
Paper and Code
Dec 29, 2017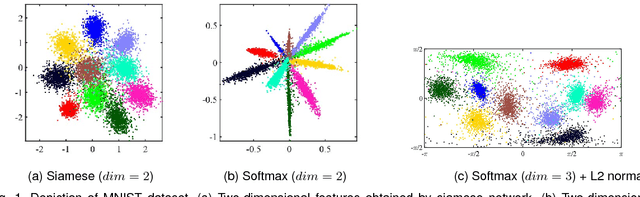
The extraction of useful deep features is important for many computer vision tasks. Deep features extracted from classification networks have proved to perform well in those tasks. To obtain features of greater usefulness, end-to-end distance metric learning (DML) has been applied to train the feature extractor directly. However, in these DML studies, there were no equitable comparisons between features extracted from a DML-based network and those from a softmax-based network. In this paper, by presenting objective comparisons between these two approaches under the same network architecture, we show that the softmax-based features perform competitive, or even better, to the state-of-the-art DML features when the size of the dataset, that is, the number of training samples per class, is large. The results suggest that softmax-based features should be properly taken into account when evaluating the performance of deep features.