 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Future Frame Prediction with Ensemble Network
Nov 16, 2020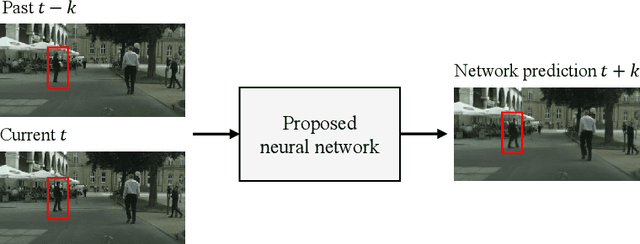
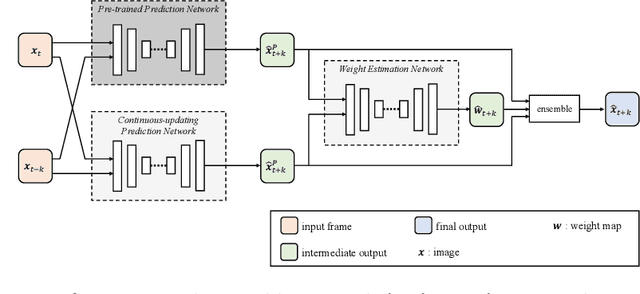

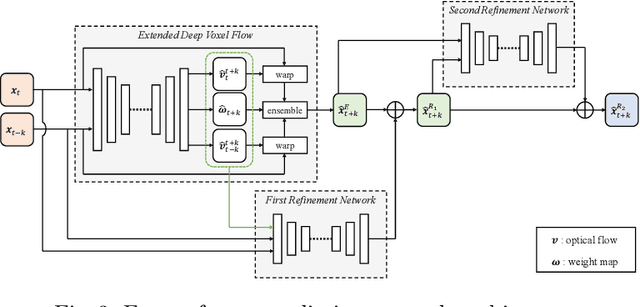
Future frame prediction in videos is a challenging problem because videos include complicated movements and large appearance changes. Learning-based future frame prediction approaches have been proposed in kinds of literature. A common limitation of the existing learning-based approaches is a mismatch of training data and test data. In the future frame prediction task, we can obtain the ground truth data by just waiting for a few frames. It means we can update the prediction model online in the test phase. Then, we propose an adaptive update framework for the future frame prediction task. The proposed adaptive updating framework consists of a pre-trained prediction network, a continuous-updating prediction network, and a weight estimation network. We also show that our pre-trained prediction model achieves comparable performance to the existing state-of-the-art approaches. We demonstrate that our approach outperforms existing methods especially for dynamically changing scenes.
Human Segmentation with Dynamic LiDAR Data
Oct 16, 2020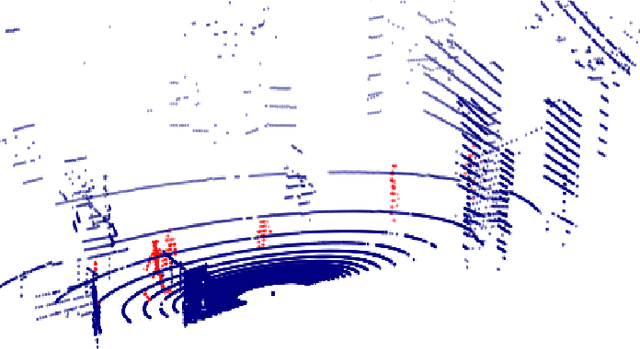
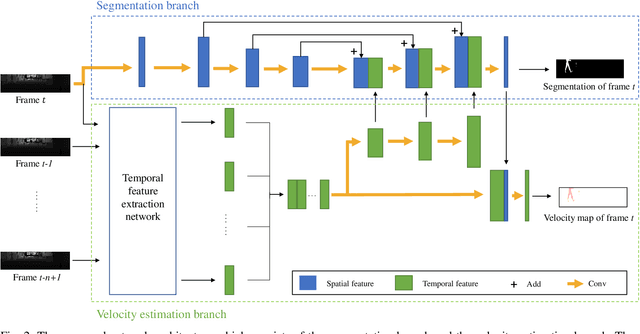
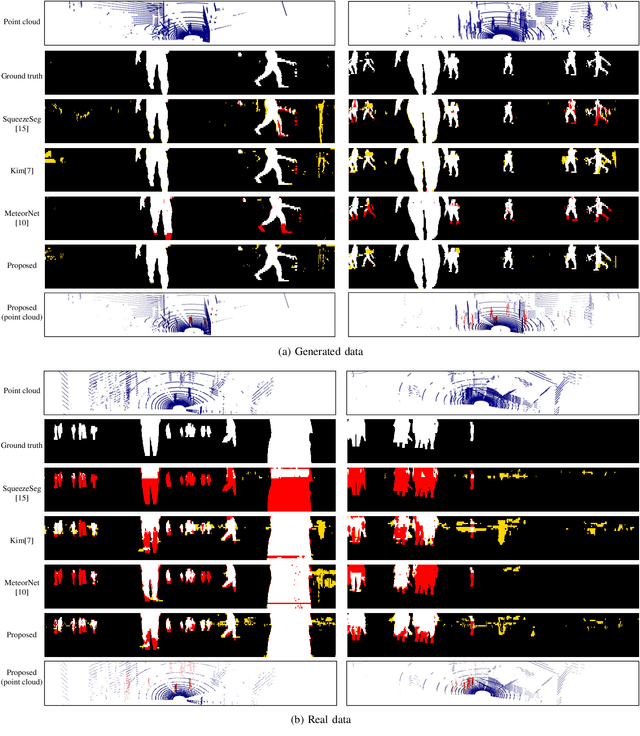
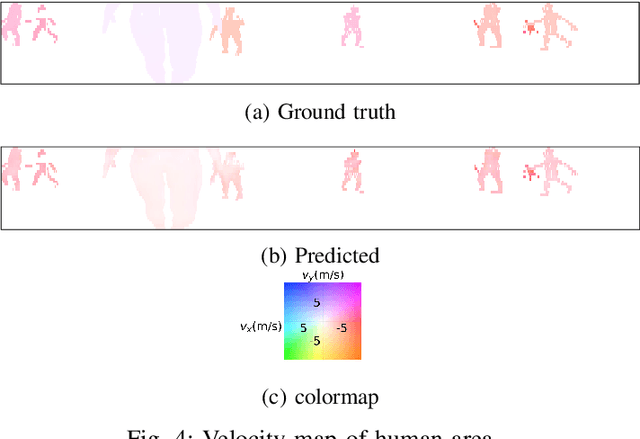
Consecutive LiDAR scans compose dynamic 3D sequences, which contain more abundant information than a single frame. Similar to the development history of image and video perception, dynamic 3D sequence perception starts to come into sight after inspiring research on static 3D data perception. This work proposes a spatio-temporal neural network for human segmentation with the dynamic LiDAR point clouds. It takes a sequence of depth images as input. It has a two-branch structure, i.e., the spatial segmentation branch and the temporal velocity estimation branch. The velocity estimation branch is designed to capture motion cues from the input sequence and then propagates them to the other branch. So that the segmentation branch segments humans according to both spatial and temporal features. These two branches are jointly learned on a generated dynamic point cloud dataset for human recognition. Our works fill in the blank of dynamic point cloud perception with the spherical representation of point cloud and achieves high accuracy. The experiments indicate that the introduction of temporal feature benefits the segmentation of dynamic point cloud.
Unsupervised Learning of Image Segmentation Based on Differentiable Feature Clustering
Jul 20, 2020



The usage of convolutional neural networks (CNNs) for unsupervised image segmentation was investigated in this study. In the proposed approach, label prediction and network parameter learning are alternately iterated to meet the following criteria: (a) pixels of similar features should be assigned the same label, (b) spatially continuous pixels should be assigned the same label, and (c) the number of unique labels should be large. Although these criteria are incompatible, the proposed approach minimizes the combination of similarity loss and spatial continuity loss to find a plausible solution of label assignment that balances the aforementioned criteria well. The contributions of this study are four-fold. First, we propose a novel end-to-end network of unsupervised image segmentation that consists of normalization and an argmax function for differentiable clustering. Second, we introduce a spatial continuity loss function that mitigates the limitations of fixed segment boundaries possessed by previous work. Third, we present an extension of the proposed method for segmentation with scribbles as user input, which showed better accuracy than existing methods while maintaining efficiency. Finally, we introduce another extension of the proposed method: unseen image segmentation by using networks pre-trained with a few reference images without re-training the networks. The effectiveness of the proposed approach was examined on several benchmark datasets of image segmentation.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Mar 11, 2020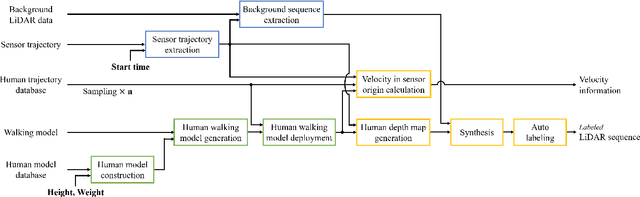

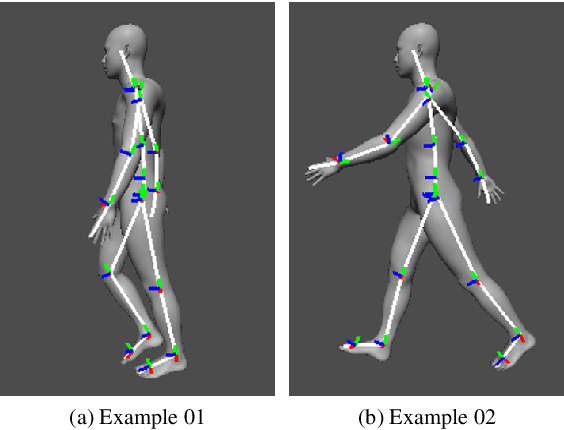

In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.
Automatic Labeled LiDAR Data Generation based on Precise Human Model
Feb 14, 2019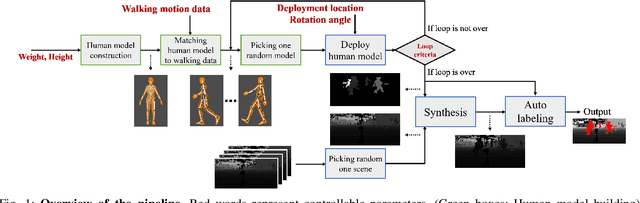
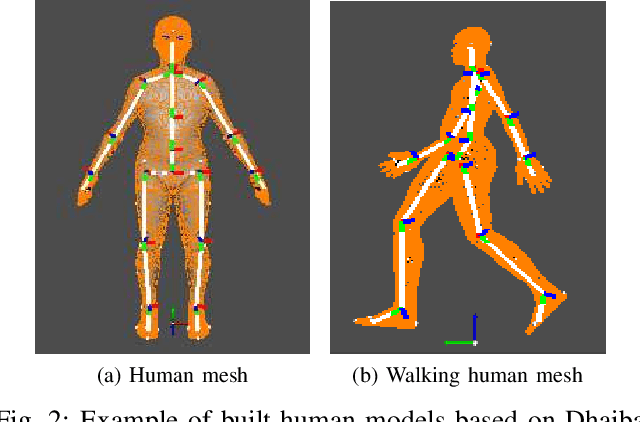

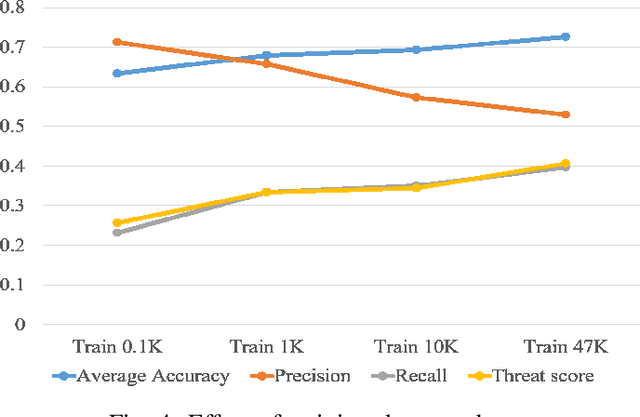
Following improvements in deep neural networks, state-of-the-art networks have been proposed for human recognition using point clouds captured by LiDAR. However, the performance of these networks strongly depends on the training data. An issue with collecting training data is labeling. Labeling by humans is necessary to obtain the ground truth label; however, labeling requires huge costs. Therefore, we propose an automatic labeled data generation pipeline, for which we can change any parameters or data generation environments. Our approach uses a human model named Dhaiba and a background of Miraikan and consequently generated realistic artificial data. We present 500k+ data generated by the proposed pipeline. This paper also describes the specification of the pipeline and data details with evaluations of various approaches.