 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Paper and Code
Jan 21, 2021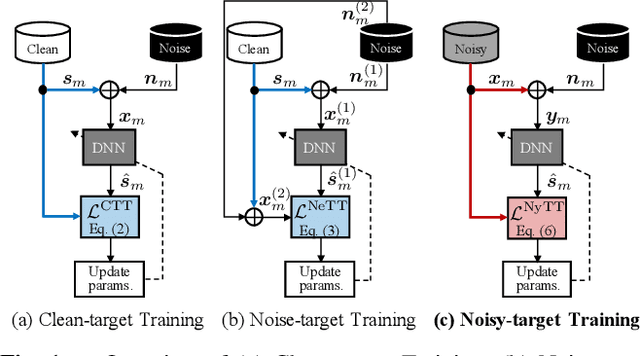
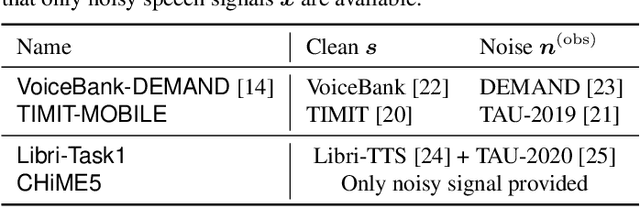
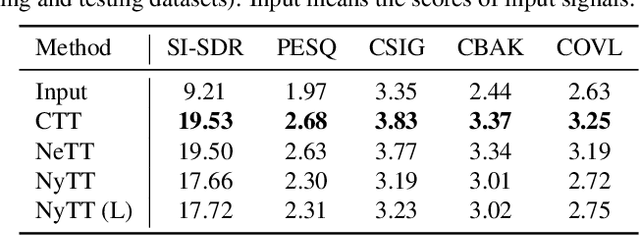

Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.