 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-Phase Speckle: Cross-Scene Stereo 3D Reconstruction via Wrapped Pre-Normalization
Mar 08, 20253D reconstruction garners increasing attention alongside the advancement of high-level image applications, where dense stereo matching (DSM) serves as a pivotal technique. Previous studies often rely on publicly available datasets for training, focusing on modifying network architectures or incorporating specialized modules to extract domain-invariant features and thus improve model robustness. In contrast, inspired by single-frame structured-light phase-shifting encoding, this study introduces RGB-Speckle, a cross-scene 3D reconstruction framework based on an active stereo camera system, designed to enhance robustness. Specifically, we propose a novel phase pre-normalization encoding-decoding method: first, we randomly perturb phase-shift maps and embed them into the three RGB channels to generate color speckle patterns; subsequently, the camera captures phase-encoded images modulated by objects as input to a stereo matching network. This technique effectively mitigates external interference and ensures consistent input data for RGB-Speckle, thereby bolstering cross-domain 3D reconstruction stability. To validate the proposed method, we conduct complex experiments: (1) construct a color speckle dataset for complex scenarios based on the proposed encoding scheme; (2) evaluate the impact of the phase pre-normalization encoding-decoding technique on 3D reconstruction accuracy; and (3) further investigate its robustness across diverse conditions. Experimental results demonstrate that the proposed RGB-Speckle model offers significant advantages in cross-domain and cross-scene 3D reconstruction tasks, enhancing model generalization and reinforcing robustness in challenging environments, thus providing a novel solution for robust 3D reconstruction research.
Two-stage Framework for Robust Speech Emotion Recognition Using Target Speaker Extraction in Human Speech Noise Conditions
Sep 29, 2024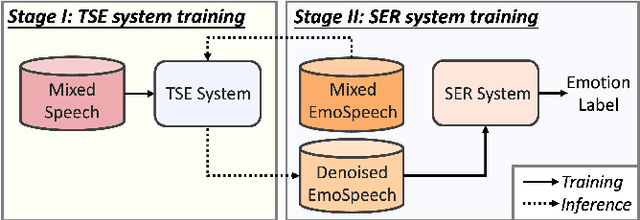
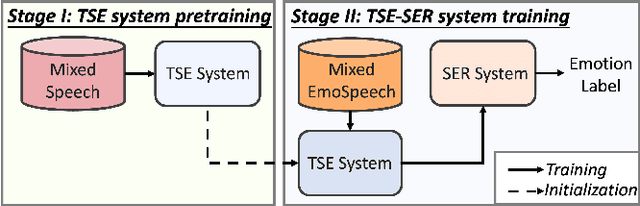
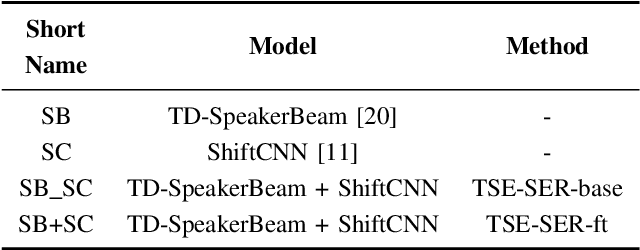
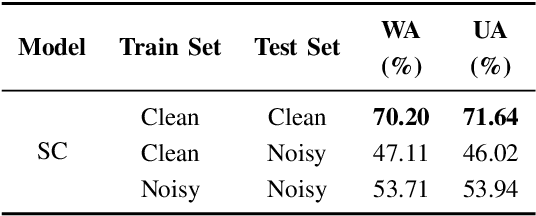
Developing a robust speech emotion recognition (SER) system in noisy conditions faces challenges posed by different noise properties. Most previous studies have not considered the impact of human speech noise, thus limiting the application scope of SER. In this paper, we propose a novel two-stage framework for the problem by cascading target speaker extraction (TSE) method and SER. We first train a TSE model to extract the speech of target speaker from a mixture. Then, in the second stage, we utilize the extracted speech for SER training. Additionally, we explore a joint training of TSE and SER models in the second stage. Our developed system achieves a 14.33% improvement in unweighted accuracy (UA) compared to a baseline without using TSE method, demonstrating the effectiveness of our framework in mitigating the impact of human speech noise. Moreover, we conduct experiments considering speaker gender, showing that our framework performs particularly well in different-gender mixture.
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, ASR Error Detection, and ASR Error Correction
Jan 24, 2024The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1\%.
On the Effectiveness of ASR Representations in Real-world Noisy Speech Emotion Recognition
Nov 14, 2023This paper proposes an efficient attempt to noisy speech emotion recognition (NSER). Conventional NSER approaches have proven effective in mitigating the impact of artificial noise sources, such as white Gaussian noise, but are limited to non-stationary noises in real-world environments due to their complexity and uncertainty. To overcome this limitation, we introduce a new method for NSER by adopting the automatic speech recognition (ASR) model as a noise-robust feature extractor to eliminate non-vocal information in noisy speech. We first obtain intermediate layer information from the ASR model as a feature representation for emotional speech and then apply this representation for the downstream NSER task. Our experimental results show that 1) the proposed method achieves better NSER performance compared with the conventional noise reduction method, 2) outperforms self-supervised learning approaches, and 3) even outperforms text-based approaches using ASR transcription or the ground truth transcription of noisy speech.