 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling
Mar 23, 2026First-order Ambisonics (FOA) is a standard spatial audio format based on spherical harmonic decomposition. Its zeroth- and first-order components capture the sound pressure and particle velocity, respectively. Recently, physics-informed neural networks have been applied to the spatial interpolation of FOA signals, regularizing the network outputs based on soft penalty terms derived from physical principles, e.g., the linearized momentum equation. In this paper, we reformulate the task so that the predicted FOA signal automatically satisfies the linearized momentum equation. Our network approximates a scalar function called velocity potential, rather than the FOA signal itself. Then, the FOA signal can be readily recovered through the partial derivatives of the velocity potential with respect to the network inputs (i.e., time and microphone position) according to physics of sound propagation. By deriving the four channels of FOA from the single-channel velocity potential, the reconstructed signal follows the physical principle at any time and position by construction. Experimental results on room impulse response reconstruction confirm the effectiveness of the proposed framework.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Sound Event Bounding Boxes
Jun 06, 2024



Sound event detection is the task of recognizing sounds and determining their extent (onset/offset times) within an audio clip. Existing systems commonly predict sound presence confidence in short time frames. Then, thresholding produces binary frame-level presence decisions, with the extent of individual events determined by merging consecutive positive frames. In this paper, we show that frame-level thresholding degrades the prediction of the event extent by coupling it with the system's sound presence confidence. We propose to decouple the prediction of event extent and confidence by introducing SEBBs, which format each sound event prediction as a tuple of a class type, extent, and overall confidence. We also propose a change-detection-based algorithm to convert legacy frame-level outputs into SEBBs. We find the algorithm significantly improves the performance of DCASE 2023 Challenge systems, boosting the state of the art from .644 to .686 PSDS1.
SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers
Apr 02, 2024



We introduce Self-Monitored Inference-Time INtervention (SMITIN), an approach for controlling an autoregressive generative music transformer using classifier probes. These simple logistic regression probes are trained on the output of each attention head in the transformer using a small dataset of audio examples both exhibiting and missing a specific musical trait (e.g., the presence/absence of drums, or real/synthetic music). We then steer the attention heads in the probe direction, ensuring the generative model output captures the desired musical trait. Additionally, we monitor the probe output to avoid adding an excessive amount of intervention into the autoregressive generation, which could lead to temporally incoherent music. We validate our results objectively and subjectively for both audio continuation and text-to-music applications, demonstrating the ability to add controls to large generative models for which retraining or even fine-tuning is impractical for most musicians. Audio samples of the proposed intervention approach are available on our demo page http://tinyurl.com/smitin .
NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection
Dec 12, 2023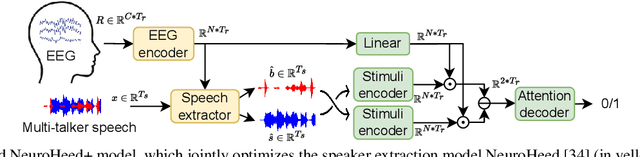

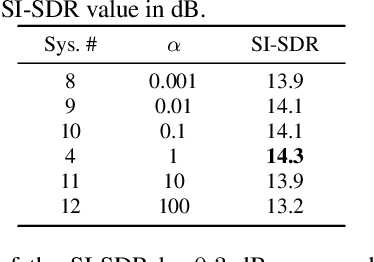
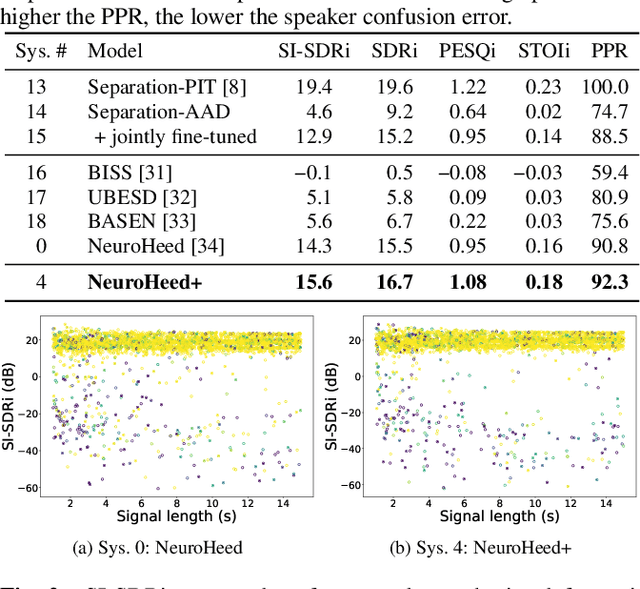
Neuro-steered speaker extraction aims to extract the listener's brain-attended speech signal from a multi-talker speech signal, in which the attention is derived from the cortical activity. This activity is usually recorded using electroencephalography (EEG) devices. Though promising, current methods often have a high speaker confusion error, where the interfering speaker is extracted instead of the attended speaker, degrading the listening experience. In this work, we aim to reduce the speaker confusion error in the neuro-steered speaker extraction model through a jointly fine-tuned auxiliary auditory attention detection model. The latter reinforces the consistency between the extracted target speech signal and the EEG representation, and also improves the EEG representation. Experimental results show that the proposed network significantly outperforms the baseline in terms of speaker confusion and overall signal quality in two-talker scenarios.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023



Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.