 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech dereverberation constrained on room impulse response characteristics
Paper and Code
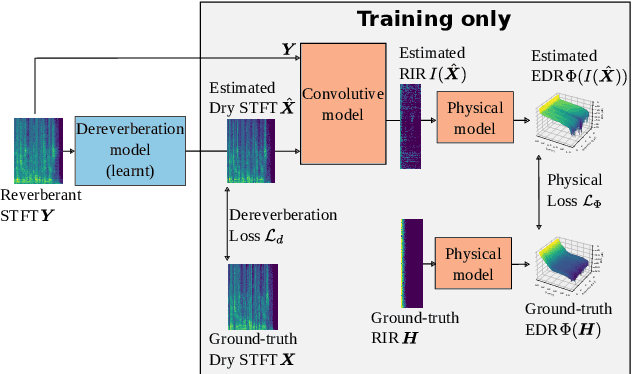
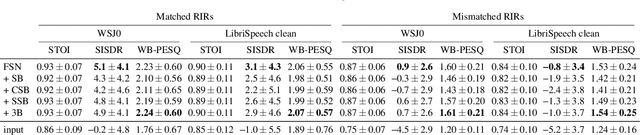
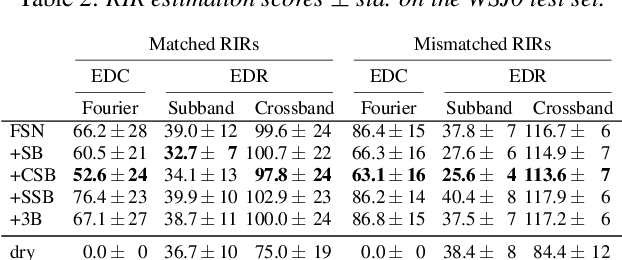
Single-channel speech dereverberation aims at extracting a dry speech signal from a recording affected by the acoustic reflections in a room. However, most current deep learning-based approaches for speech dereverberation are not interpretable for room acoustics, and can be considered as black-box systems in that regard. In this work, we address this problem by regularizing the training loss using a novel physical coherence loss which encourages the room impulse response (RIR) induced by the dereverberated output of the model to match the acoustic properties of the room in which the signal was recorded. Our investigation demonstrates the preservation of the original dereverberated signal alongside the provision of a more physically coherent RIR.