 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Transduction with Graph-based Supervision
Paper and Code
Nov 01, 2021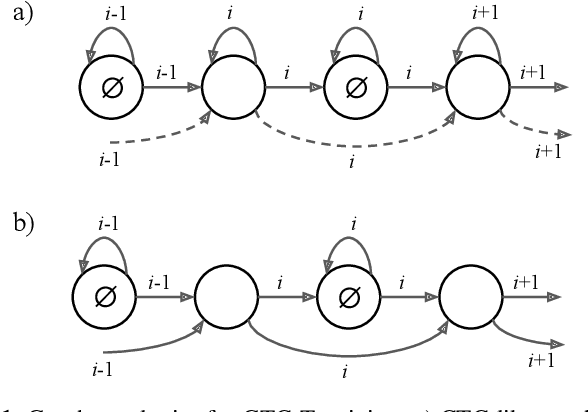
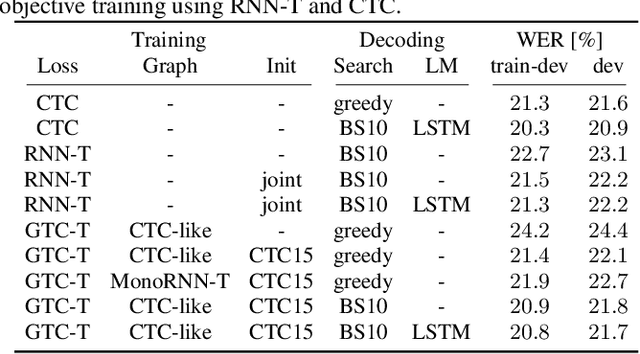
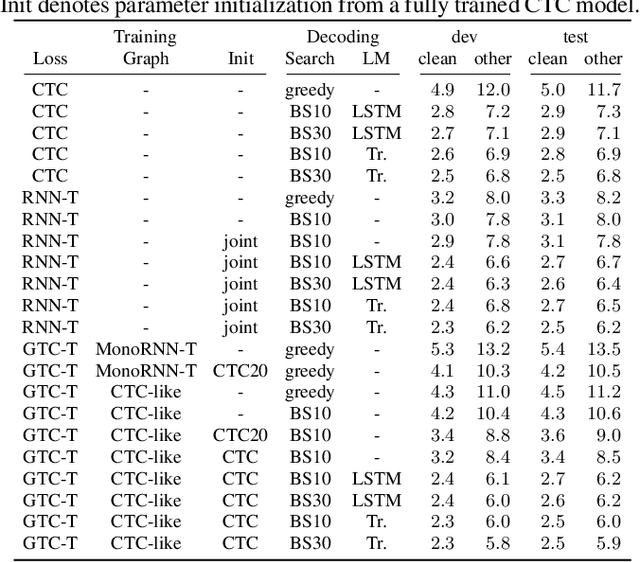
The recurrent neural network transducer (RNN-T) objective plays a major role in building today's best automatic speech recognition (ASR) systems for production. Similarly to the connectionist temporal classification (CTC) objective, the RNN-T loss uses specific rules that define how a set of alignments is generated to form a lattice for the full-sum training. However, it is yet largely unknown if these rules are optimal and do lead to the best possible ASR results. In this work, we present a new transducer objective function that generalizes the RNN-T loss to accept a graph representation of the labels, thus providing a flexible and efficient framework to manipulate training lattices, for example for restricting alignments or studying different transition rules. We demonstrate that transducer-based ASR with CTC-like lattice achieves better results compared to standard RNN-T, while also ensuring a strictly monotonic alignment, which will allow better optimization of the decoding procedure. For example, the proposed CTC-like transducer system achieves a word error rate of 5.9% for the test-other condition of LibriSpeech, corresponding to an improvement of 4.8% relative to an equivalent RNN-T based system.