 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021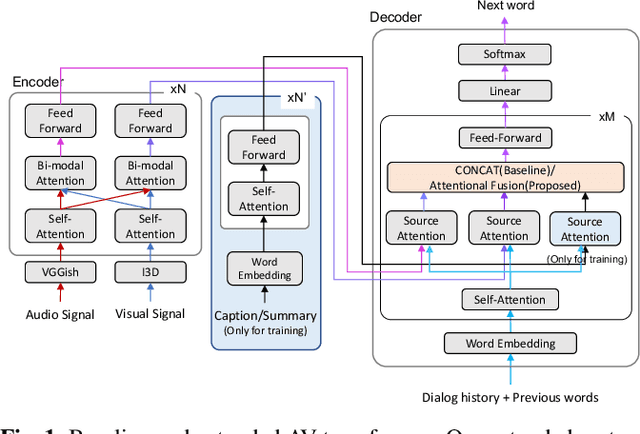
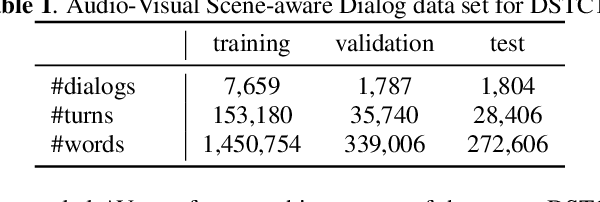
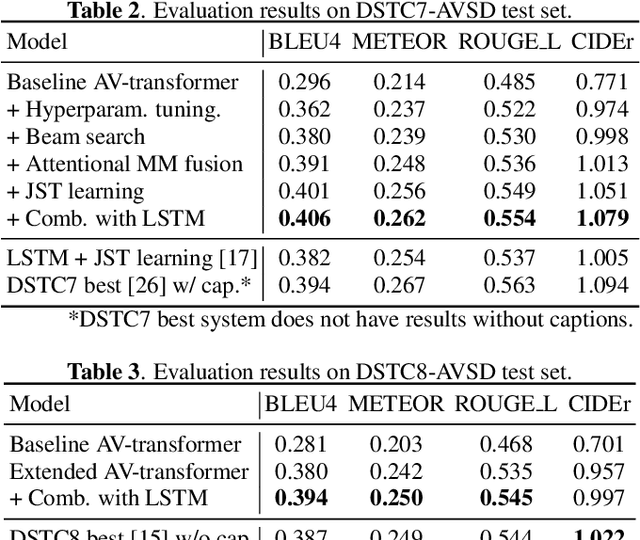
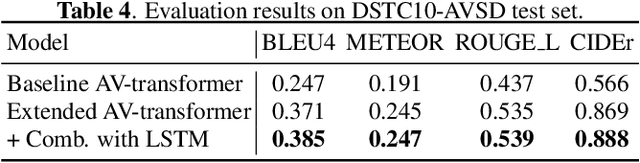
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.