 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Representations with Caption Annotations
Paper and Code
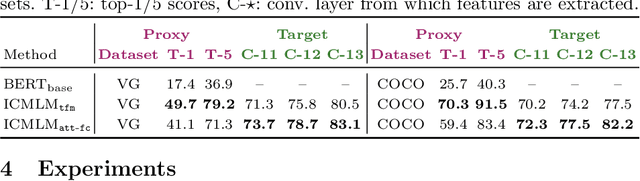

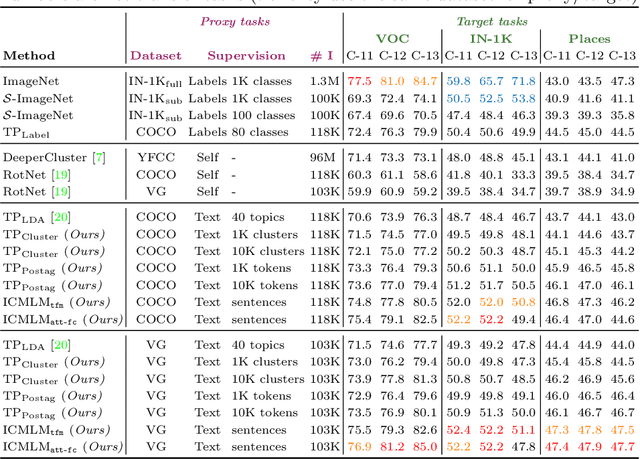

Pretraining general-purpose visual features has become a crucial part of tackling many computer vision tasks. While one can learn such features on the extensively-annotated ImageNet dataset, recent approaches have looked at ways to allow for noisy, fewer, or even no annotations to perform such pretraining. Starting from the observation that captioned images are easily crawlable, we argue that this overlooked source of information can be exploited to supervise the training of visual representations. To do so, motivated by the recent progresses in language models, we introduce {\em image-conditioned masked language modeling} (ICMLM) -- a proxy task to learn visual representations over image-caption pairs. ICMLM consists in predicting masked words in captions by relying on visual cues. To tackle this task, we propose hybrid models, with dedicated visual and textual encoders, and we show that the visual representations learned as a by-product of solving this task transfer well to a variety of target tasks. Our experiments confirm that image captions can be leveraged to inject global and localized semantic information into visual representations. Project website: https://europe.naverlabs.com/icmlm.