 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Embedding Spectrum for Recommendation
Jun 17, 2024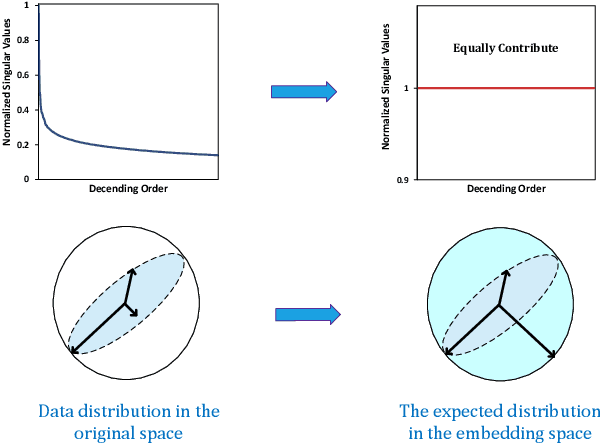
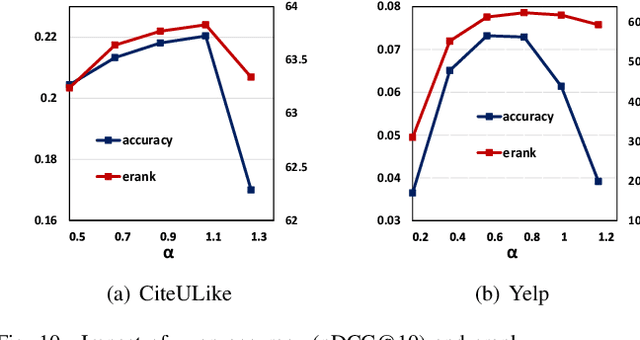
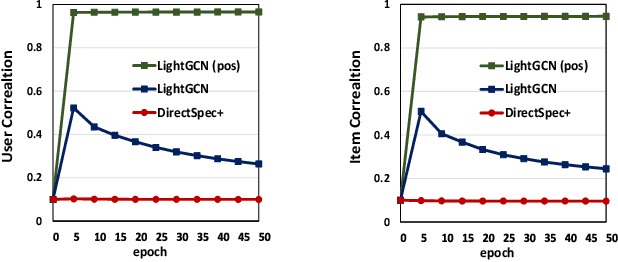
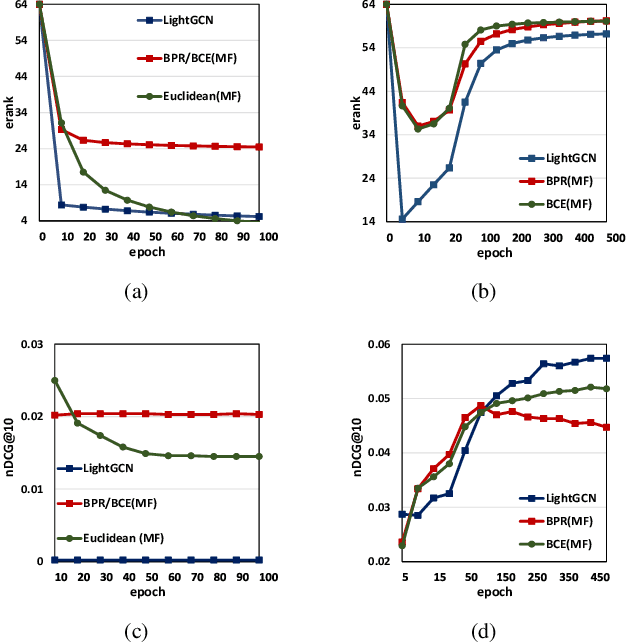
Modern recommender systems heavily rely on high-quality representations learned from high-dimensional sparse data. While significant efforts have been invested in designing powerful algorithms for extracting user preferences, the factors contributing to good representations have remained relatively unexplored. In this work, we shed light on an issue in the existing pair-wise learning paradigm (i.e., the embedding collapse problem), that the representations tend to span a subspace of the whole embedding space, leading to a suboptimal solution and reducing the model capacity. Specifically, optimization on observed interactions is equivalent to a low pass filter causing users/items to have the same representations and resulting in a complete collapse. While negative sampling acts as a high pass filter to alleviate the collapse by balancing the embedding spectrum, its effectiveness is only limited to certain losses, which still leads to an incomplete collapse. To tackle this issue, we propose a novel method called DirectSpec, acting as a reliable all pass filter to balance the spectrum distribution of the embeddings during training, ensuring that users/items effectively span the entire embedding space. Additionally, we provide a thorough analysis of DirectSpec from a decorrelation perspective and propose an enhanced variant, DirectSpec+, which employs self-paced gradients to optimize irrelevant samples more effectively. Moreover, we establish a close connection between DirectSpec+ and uniformity, demonstrating that contrastive learning (CL) can alleviate the collapse issue by indirectly balancing the spectrum. Finally, we implement DirectSpec and DirectSpec+ on two popular recommender models: MF and LightGCN. Our experimental results demonstrate its effectiveness and efficiency over competitive baselines.
How Powerful is Graph Filtering for Recommendation
Jun 13, 2024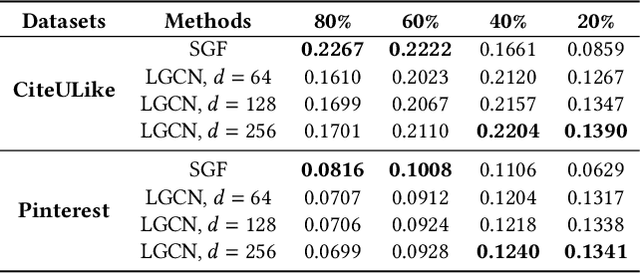
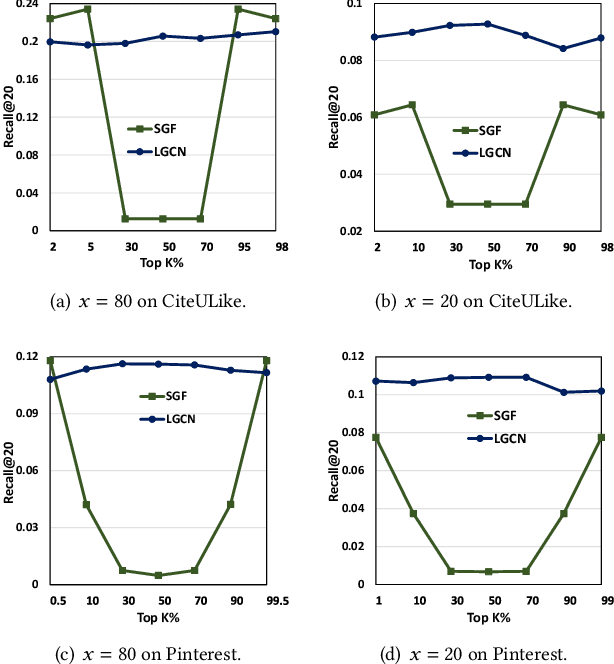
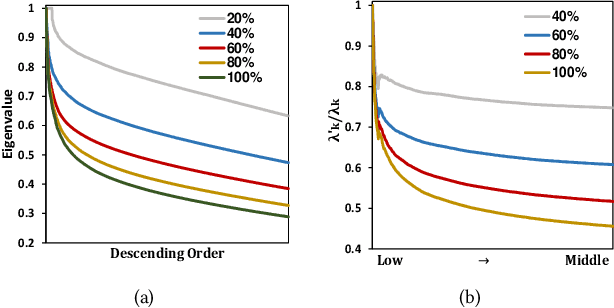
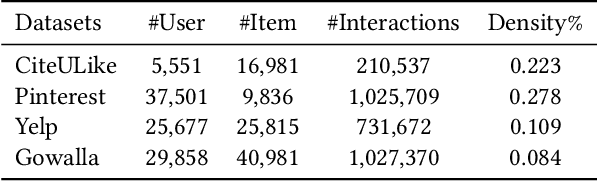
It has been shown that the effectiveness of graph convolutional network (GCN) for recommendation is attributed to the spectral graph filtering. Most GCN-based methods consist of a graph filter or followed by a low-rank mapping optimized based on supervised training. However, we show two limitations suppressing the power of graph filtering: (1) Lack of generality. Due to the varied noise distribution, graph filters fail to denoise sparse data where noise is scattered across all frequencies, while supervised training results in worse performance on dense data where noise is concentrated in middle frequencies that can be removed by graph filters without training. (2) Lack of expressive power. We theoretically show that linear GCN (LGCN) that is effective on collaborative filtering (CF) cannot generate arbitrary embeddings, implying the possibility that optimal data representation might be unreachable. To tackle the first limitation, we show close relation between noise distribution and the sharpness of spectrum where a sharper spectral distribution is more desirable causing data noise to be separable from important features without training. Based on this observation, we propose a generalized graph normalization G^2N to adjust the sharpness of spectral distribution in order to redistribute data noise to assure that it can be removed by graph filtering without training. As for the second limitation, we propose an individualized graph filter (IGF) adapting to the different confidence levels of the user preference that interactions can reflect, which is proved to be able to generate arbitrary embeddings. By simplifying LGCN, we further propose a simplified graph filtering (SGFCF) which only requires the top-K singular values for recommendation. Finally, experimental results on four datasets with different density settings demonstrate the effectiveness and efficiency of our proposed methods.
Less is More: Reweighting Important Spectral Graph Features for Recommendation
Apr 24, 2022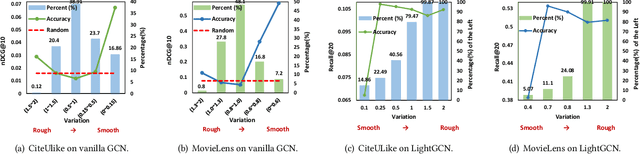
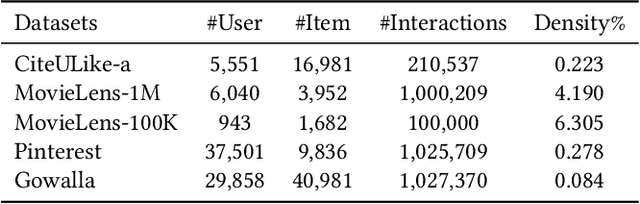
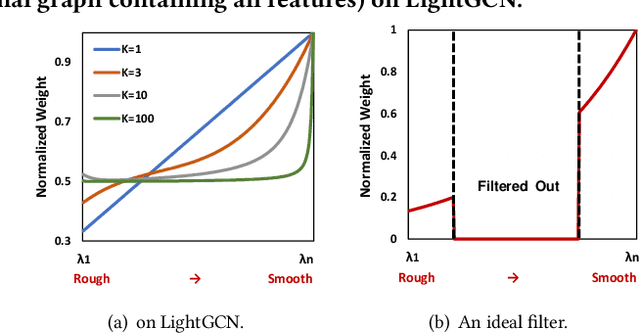
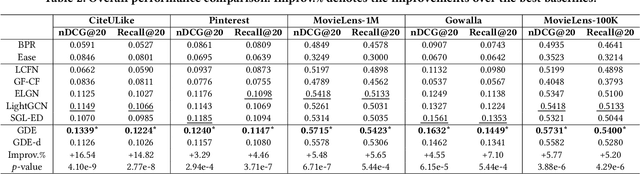
As much as Graph Convolutional Networks (GCNs) have shown tremendous success in recommender systems and collaborative filtering (CF), the mechanism of how they, especially the core components (\textit{i.e.,} neighborhood aggregation) contribute to recommendation has not been well studied. To unveil the effectiveness of GCNs for recommendation, we first analyze them in a spectral perspective and discover two important findings: (1) only a small portion of spectral graph features that emphasize the neighborhood smoothness and difference contribute to the recommendation accuracy, whereas most graph information can be considered as noise that even reduces the performance, and (2) repetition of the neighborhood aggregation emphasizes smoothed features and filters out noise information in an ineffective way. Based on the two findings above, we propose a new GCN learning scheme for recommendation by replacing neihgborhood aggregation with a simple yet effective Graph Denoising Encoder (GDE), which acts as a band pass filter to capture important graph features. We show that our proposed method alleviates the over-smoothing and is comparable to an indefinite-layer GCN that can take any-hop neighborhood into consideration. Finally, we dynamically adjust the gradients over the negative samples to expedite model training without introducing additional complexity. Extensive experiments on five real-world datasets show that our proposed method not only outperforms state-of-the-arts but also achieves 12x speedup over LightGCN.
FANG: Leveraging Social Context for Fake News Detection Using Graph Representation
Aug 18, 2020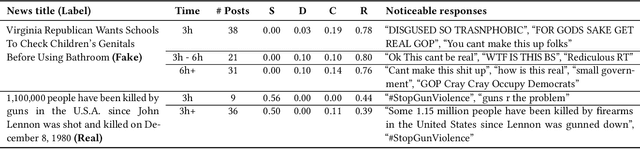
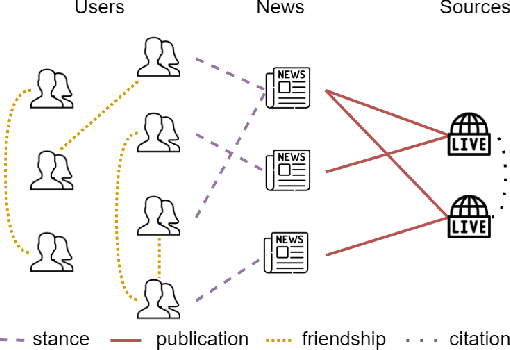
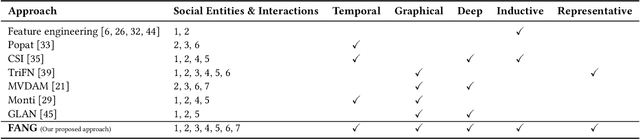
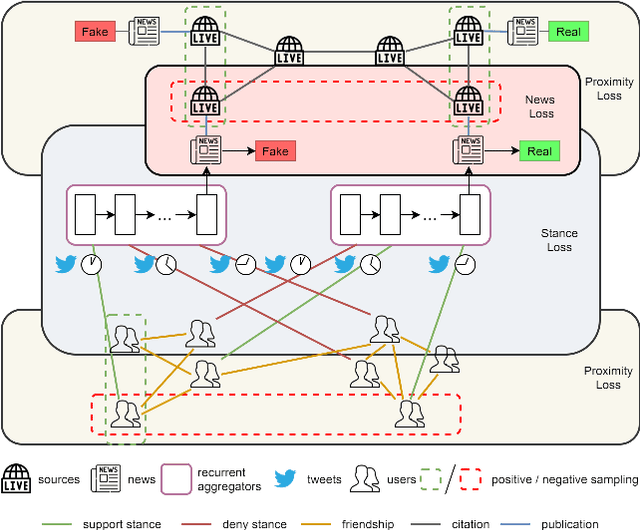
We propose Factual News Graph (FANG), a novel graphical social context representation and learning framework for fake news detection. Unlike previous contextual models that have targeted performance, our focus is on representation learning. Compared to transductive models, FANG is scalable in training as it does not have to maintain all nodes, and it is efficient at inference time, without the need to re-process the entire graph. Our experimental results show that FANG is better at capturing the social context into a high fidelity representation, compared to recent graphical and non-graphical models. In particular, FANG yields significant improvements for the task of fake news detection, and it is robust in the case of limited training data. We further demonstrate that the representations learned by FANG generalize to related tasks, such as predicting the factuality of reporting of a news medium.
Neural Multi-Task Learning for Citation Function and Provenance
Nov 18, 2018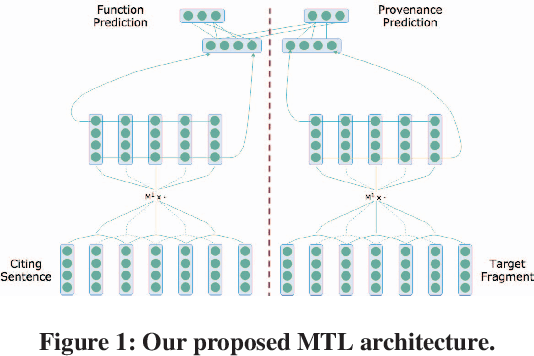
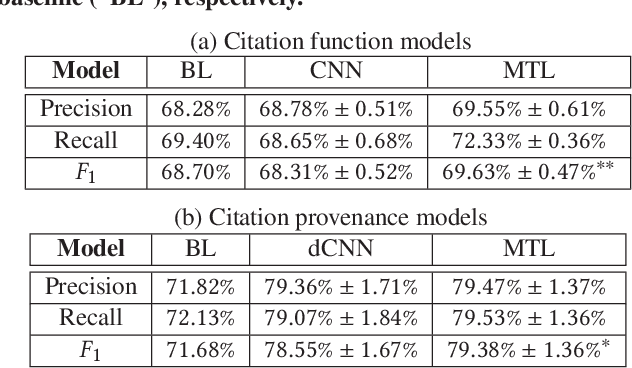
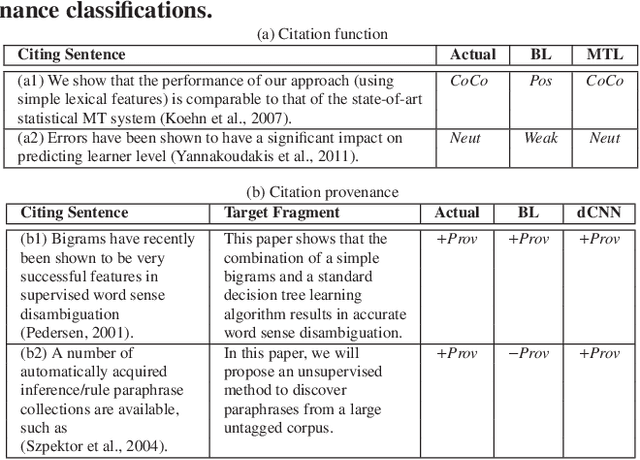
Citation function and provenance are two cornerstone tasks in citation analysis. Given a citation, the former task determines its rhetorical role, while the latter locates the text in the cited paper that contains the relevant cited information. We hypothesize that these two tasks are synergistically related, and build a model that validates this claim. For both tasks, we show that a single-layer convolutional neural network (CNN) is able to surpass the performance of existing state-of-the-art baselines. More importantly, we show that the two tasks are indeed synergistic: by training both tasks in one go using multi-task learning, we demonstrate additional performance gains in both tasks. Altogether, our contributions outperform the current state-of-the-arts by ~2% and ~7%, with statistical significance for citation function and citation provenance prediction tasks, respectively.
Abstractive Meeting Summarization UsingDependency Graph Fusion
Sep 22, 2016


Automatic summarization techniques on meeting conversations developed so far have been primarily extractive, resulting in poor summaries. To improve this, we propose an approach to generate abstractive summaries by fusing important content from several utterances. Any meeting is generally comprised of several discussion topic segments. For each topic segment within a meeting conversation, we aim to generate a one sentence summary from the most important utterances using an integer linear programming-based sentence fusion approach. Experimental results show that our method can generate more informative summaries than the baselines.
Multi-document abstractive summarization using ILP based multi-sentence compression
Sep 22, 2016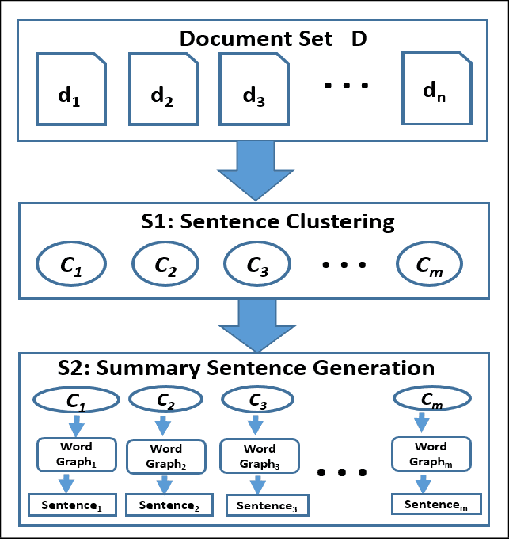
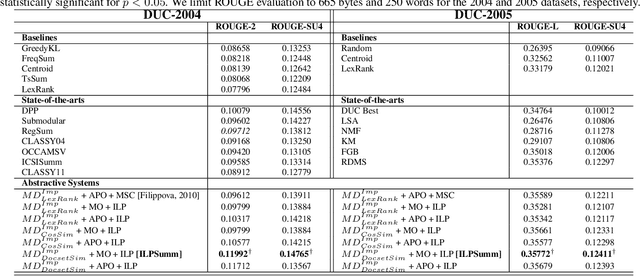
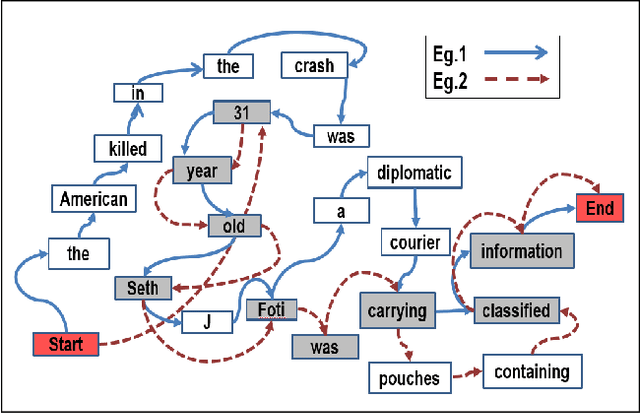
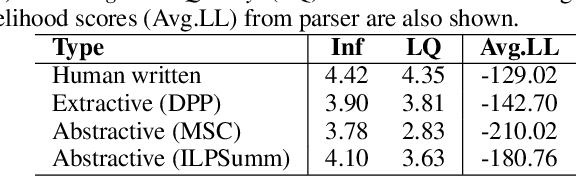
Abstractive summarization is an ideal form of summarization since it can synthesize information from multiple documents to create concise informative summaries. In this work, we aim at developing an abstractive summarizer. First, our proposed approach identifies the most important document in the multi-document set. The sentences in the most important document are aligned to sentences in other documents to generate clusters of similar sentences. Second, we generate K-shortest paths from the sentences in each cluster using a word-graph structure. Finally, we select sentences from the set of shortest paths generated from all the clusters employing a novel integer linear programming (ILP) model with the objective of maximizing information content and readability of the final summary. Our ILP model represents the shortest paths as binary variables and considers the length of the path, information score and linguistic quality score in the objective function. Experimental results on the DUC 2004 and 2005 multi-document summarization datasets show that our proposed approach outperforms all the baselines and state-of-the-art extractive summarizers as measured by the ROUGE scores. Our method also outperforms a recent abstractive summarization technique. In manual evaluation, our approach also achieves promising results on informativeness and readability.
Generating Abstractive Summaries from Meeting Transcripts
Sep 22, 2016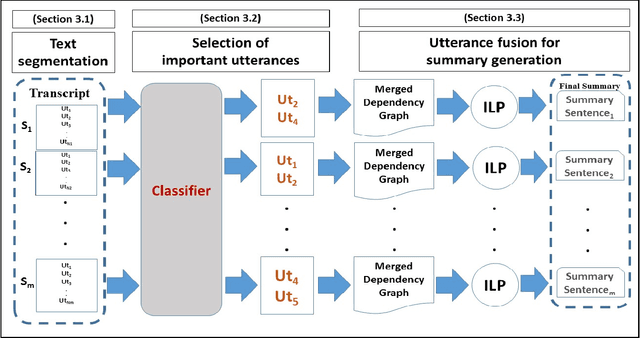
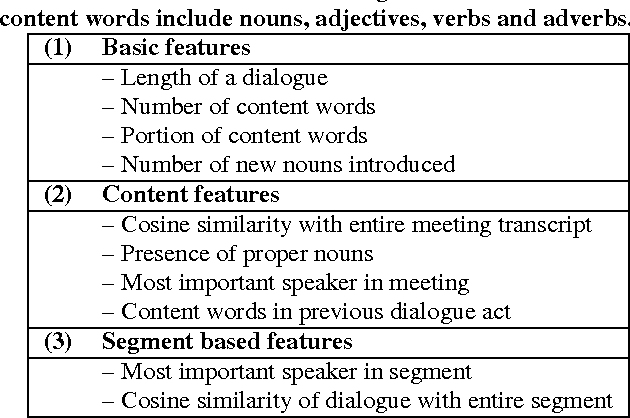
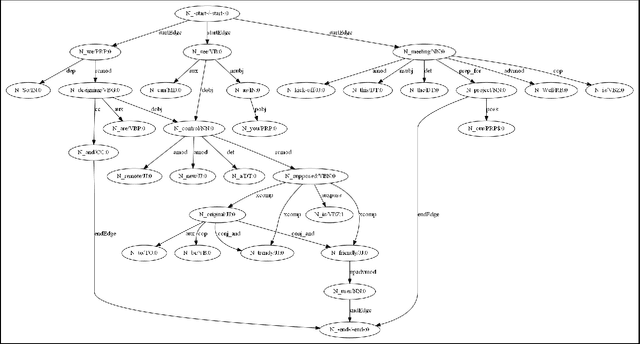
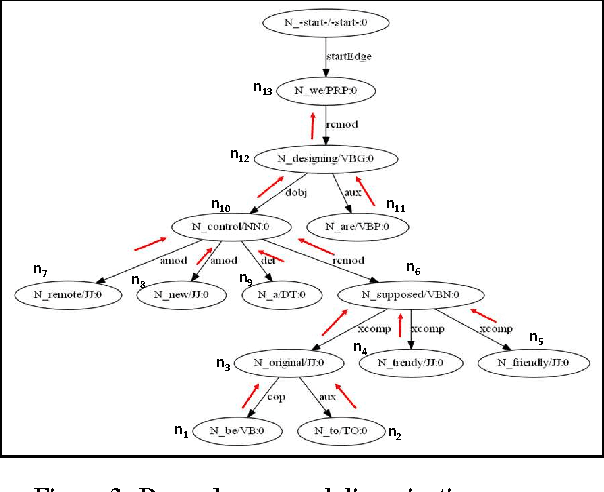
Summaries of meetings are very important as they convey the essential content of discussions in a concise form. Generally, it is time consuming to read and understand the whole documents. Therefore, summaries play an important role as the readers are interested in only the important context of discussions. In this work, we address the task of meeting document summarization. Automatic summarization systems on meeting conversations developed so far have been primarily extractive, resulting in unacceptable summaries that are hard to read. The extracted utterances contain disfluencies that affect the quality of the extractive summaries. To make summaries much more readable, we propose an approach to generating abstractive summaries by fusing important content from several utterances. We first separate meeting transcripts into various topic segments, and then identify the important utterances in each segment using a supervised learning approach. The important utterances are then combined together to generate a one-sentence summary. In the text generation step, the dependency parses of the utterances in each segment are combined together to create a directed graph. The most informative and well-formed sub-graph obtained by integer linear programming (ILP) is selected to generate a one-sentence summary for each topic segment. The ILP formulation reduces disfluencies by leveraging grammatical relations that are more prominent in non-conversational style of text, and therefore generates summaries that is comparable to human-written abstractive summaries. Experimental results show that our method can generate more informative summaries than the baselines. In addition, readability assessments by human judges as well as log-likelihood estimates obtained from the dependency parser show that our generated summaries are significantly readable and well-formed.
Product Review Summarization based on Facet Identification and Sentence Clustering
Oct 07, 2011
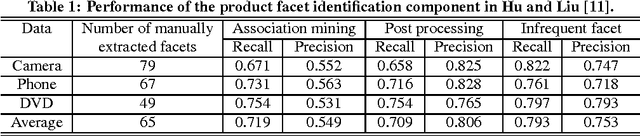
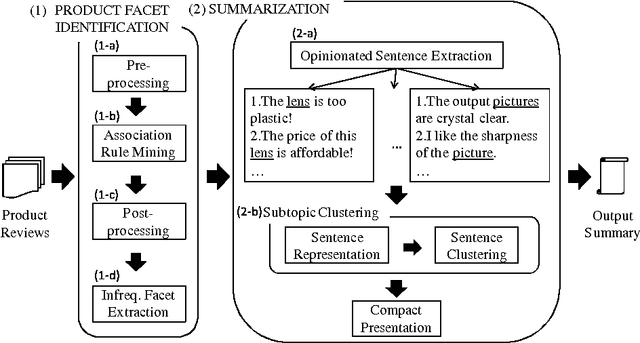
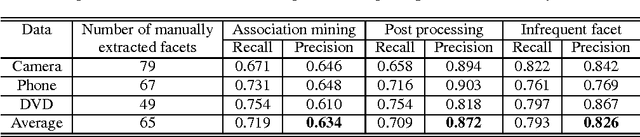
Product review nowadays has become an important source of information, not only for customers to find opinions about products easily and share their reviews with peers, but also for product manufacturers to get feedback on their products. As the number of product reviews grows, it becomes difficult for users to search and utilize these resources in an efficient way. In this work, we build a product review summarization system that can automatically process a large collection of reviews and aggregate them to generate a concise summary. More importantly, the drawback of existing product summarization systems is that they cannot provide the underlying reasons to justify users' opinions. In our method, we solve this problem by applying clustering, prior to selecting representative candidates for summarization.