 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Embedding Spectrum for Recommendation
Jun 17, 2024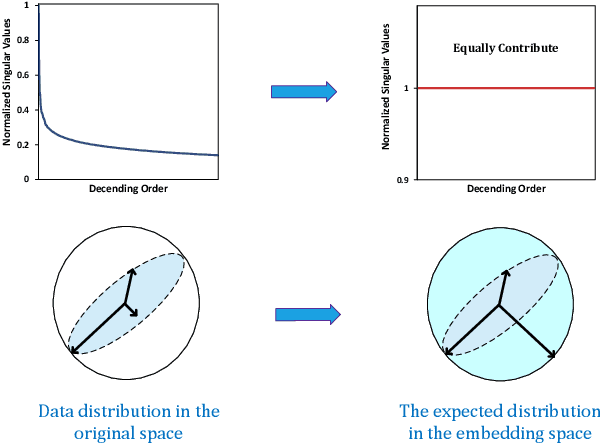
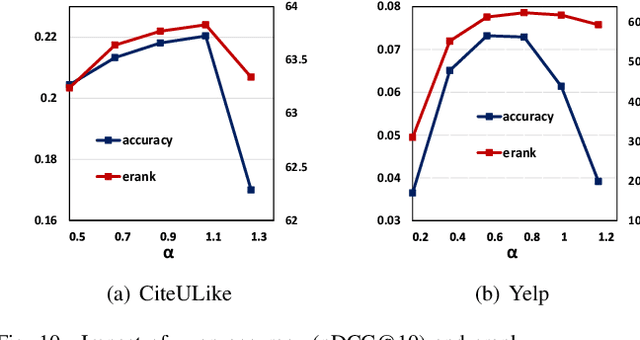
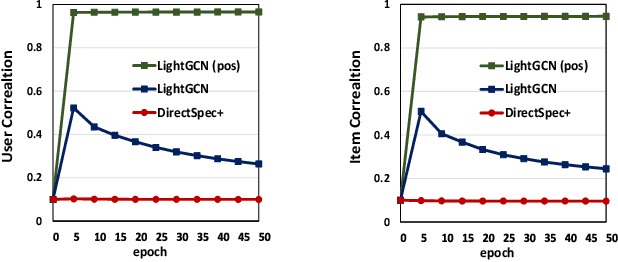
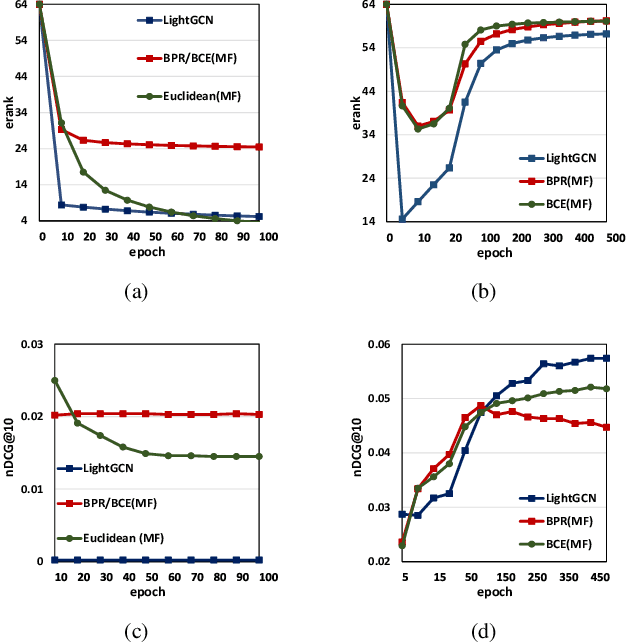
Modern recommender systems heavily rely on high-quality representations learned from high-dimensional sparse data. While significant efforts have been invested in designing powerful algorithms for extracting user preferences, the factors contributing to good representations have remained relatively unexplored. In this work, we shed light on an issue in the existing pair-wise learning paradigm (i.e., the embedding collapse problem), that the representations tend to span a subspace of the whole embedding space, leading to a suboptimal solution and reducing the model capacity. Specifically, optimization on observed interactions is equivalent to a low pass filter causing users/items to have the same representations and resulting in a complete collapse. While negative sampling acts as a high pass filter to alleviate the collapse by balancing the embedding spectrum, its effectiveness is only limited to certain losses, which still leads to an incomplete collapse. To tackle this issue, we propose a novel method called DirectSpec, acting as a reliable all pass filter to balance the spectrum distribution of the embeddings during training, ensuring that users/items effectively span the entire embedding space. Additionally, we provide a thorough analysis of DirectSpec from a decorrelation perspective and propose an enhanced variant, DirectSpec+, which employs self-paced gradients to optimize irrelevant samples more effectively. Moreover, we establish a close connection between DirectSpec+ and uniformity, demonstrating that contrastive learning (CL) can alleviate the collapse issue by indirectly balancing the spectrum. Finally, we implement DirectSpec and DirectSpec+ on two popular recommender models: MF and LightGCN. Our experimental results demonstrate its effectiveness and efficiency over competitive baselines.
How Powerful is Graph Filtering for Recommendation
Jun 13, 2024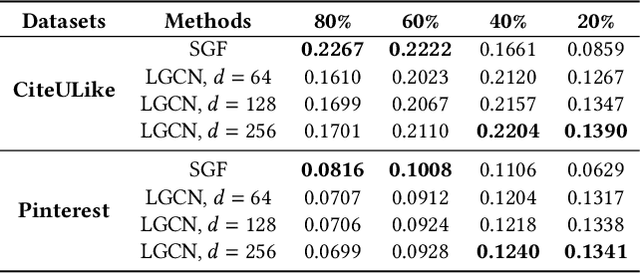
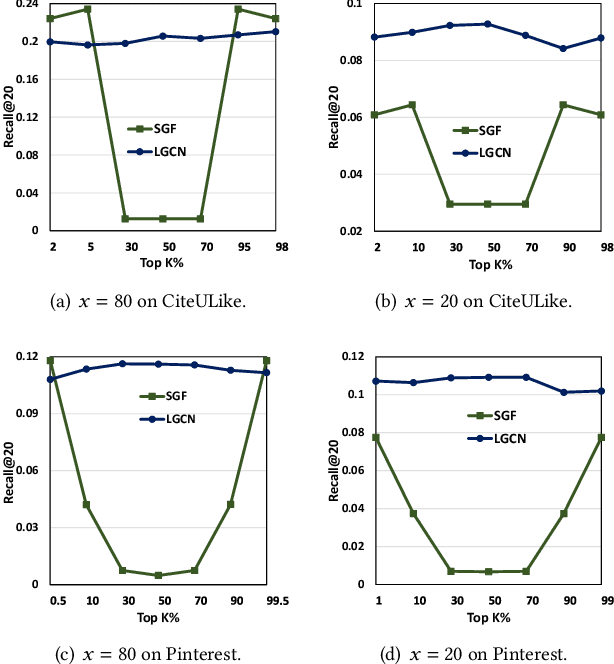
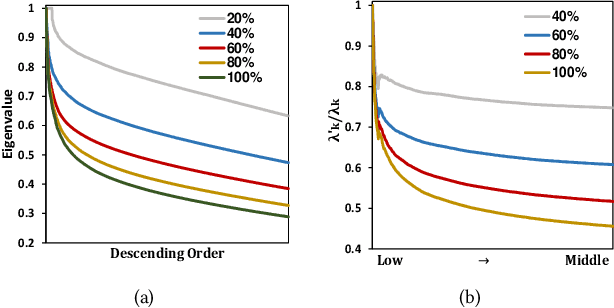
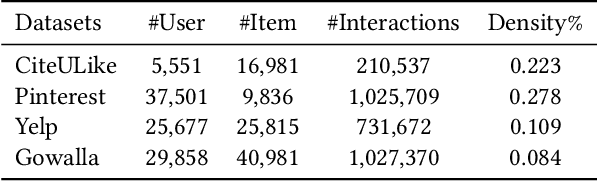
It has been shown that the effectiveness of graph convolutional network (GCN) for recommendation is attributed to the spectral graph filtering. Most GCN-based methods consist of a graph filter or followed by a low-rank mapping optimized based on supervised training. However, we show two limitations suppressing the power of graph filtering: (1) Lack of generality. Due to the varied noise distribution, graph filters fail to denoise sparse data where noise is scattered across all frequencies, while supervised training results in worse performance on dense data where noise is concentrated in middle frequencies that can be removed by graph filters without training. (2) Lack of expressive power. We theoretically show that linear GCN (LGCN) that is effective on collaborative filtering (CF) cannot generate arbitrary embeddings, implying the possibility that optimal data representation might be unreachable. To tackle the first limitation, we show close relation between noise distribution and the sharpness of spectrum where a sharper spectral distribution is more desirable causing data noise to be separable from important features without training. Based on this observation, we propose a generalized graph normalization G^2N to adjust the sharpness of spectral distribution in order to redistribute data noise to assure that it can be removed by graph filtering without training. As for the second limitation, we propose an individualized graph filter (IGF) adapting to the different confidence levels of the user preference that interactions can reflect, which is proved to be able to generate arbitrary embeddings. By simplifying LGCN, we further propose a simplified graph filtering (SGFCF) which only requires the top-K singular values for recommendation. Finally, experimental results on four datasets with different density settings demonstrate the effectiveness and efficiency of our proposed methods.
SVD-GCN: A Simplified Graph Convolution Paradigm for Recommendation
Aug 26, 2022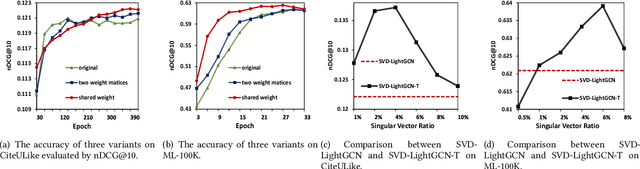
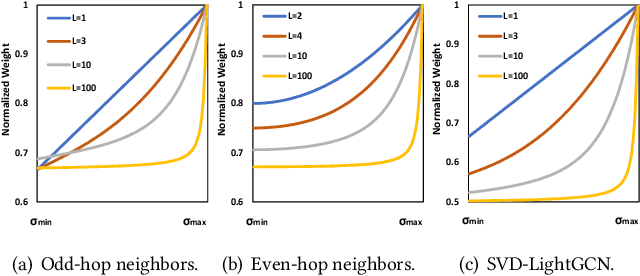
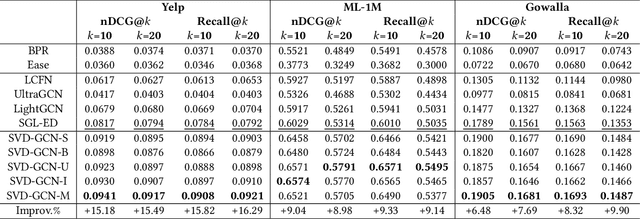
With the tremendous success of Graph Convolutional Networks (GCNs), they have been widely applied to recommender systems and have shown promising performance. However, most GCN-based methods rigorously stick to a common GCN learning paradigm and suffer from two limitations: (1) the limited scalability due to the high computational cost and slow training convergence; (2) the notorious over-smoothing issue which reduces performance as stacking graph convolution layers. We argue that the above limitations are due to the lack of a deep understanding of GCN-based methods. To this end, we first investigate what design makes GCN effective for recommendation. By simplifying LightGCN, we show the close connection between GCN-based and low-rank methods such as Singular Value Decomposition (SVD) and Matrix Factorization (MF), where stacking graph convolution layers is to learn a low-rank representation by emphasizing (suppressing) components with larger (smaller) singular values. Based on this observation, we replace the core design of GCN-based methods with a flexible truncated SVD and propose a simplified GCN learning paradigm dubbed SVD-GCN, which only exploits $K$-largest singular vectors for recommendation. To alleviate the over-smoothing issue, we propose a renormalization trick to adjust the singular value gap, resulting in significant improvement. Extensive experiments on three real-world datasets show that our proposed SVD-GCN not only significantly outperforms state-of-the-arts but also achieves over 100x and 10x speedups over LightGCN and MF, respectively.
Less is More: Reweighting Important Spectral Graph Features for Recommendation
Apr 24, 2022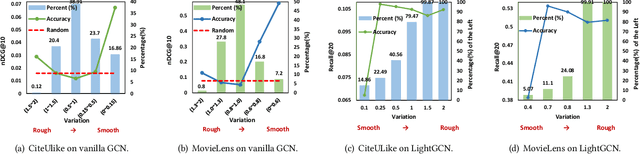
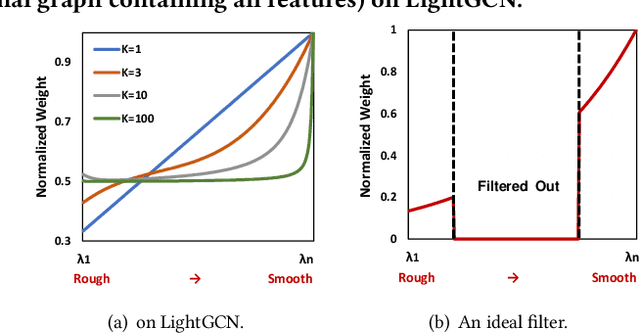
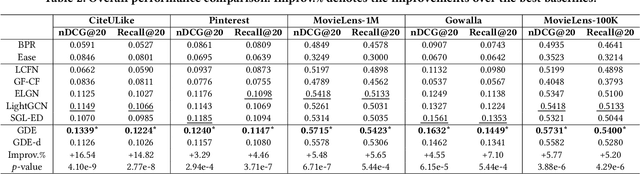
As much as Graph Convolutional Networks (GCNs) have shown tremendous success in recommender systems and collaborative filtering (CF), the mechanism of how they, especially the core components (\textit{i.e.,} neighborhood aggregation) contribute to recommendation has not been well studied. To unveil the effectiveness of GCNs for recommendation, we first analyze them in a spectral perspective and discover two important findings: (1) only a small portion of spectral graph features that emphasize the neighborhood smoothness and difference contribute to the recommendation accuracy, whereas most graph information can be considered as noise that even reduces the performance, and (2) repetition of the neighborhood aggregation emphasizes smoothed features and filters out noise information in an ineffective way. Based on the two findings above, we propose a new GCN learning scheme for recommendation by replacing neihgborhood aggregation with a simple yet effective Graph Denoising Encoder (GDE), which acts as a band pass filter to capture important graph features. We show that our proposed method alleviates the over-smoothing and is comparable to an indefinite-layer GCN that can take any-hop neighborhood into consideration. Finally, we dynamically adjust the gradients over the negative samples to expedite model training without introducing additional complexity. Extensive experiments on five real-world datasets show that our proposed method not only outperforms state-of-the-arts but also achieves 12x speedup over LightGCN.
A Robust Hierarchical Graph Convolutional Network Model for Collaborative Filtering
Apr 30, 2020
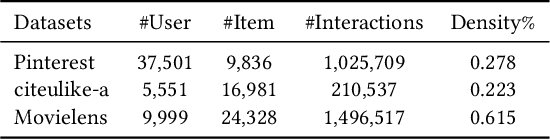


Graph Convolutional Network (GCN) has achieved great success and has been applied in various fields including recommender systems. However, GCN still suffers from many issues such as training difficulties, over-smoothing, vulnerable to adversarial attacks, etc. Distinct from current GCN-based methods which simply employ GCN for recommendation, in this paper we are committed to build a robust GCN model for collaborative filtering. Firstly, we argue that recursively incorporating messages from different order neighborhood mixes distinct node messages indistinguishably, which increases the training difficulty; instead we choose to separately aggregate different order neighbor messages with a simple GCN model which has been shown effective; then we accumulate them together in a hierarchical way without introducing additional model parameters. Secondly, we propose a solution to alleviate over-smoothing by randomly dropping out neighbor messages at each layer, which also well prevents over-fitting and enhances the robustness. Extensive experiments on three real-world datasets demonstrate the effectiveness and robustness of our model.