 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Embedding Spectrum for Recommendation
Paper and Code
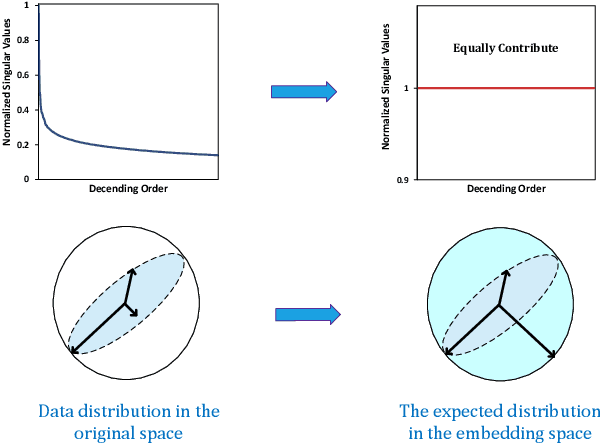
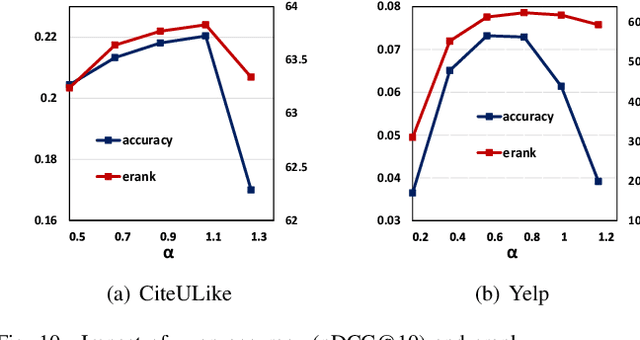
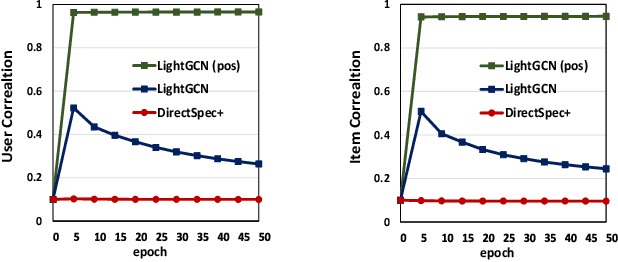
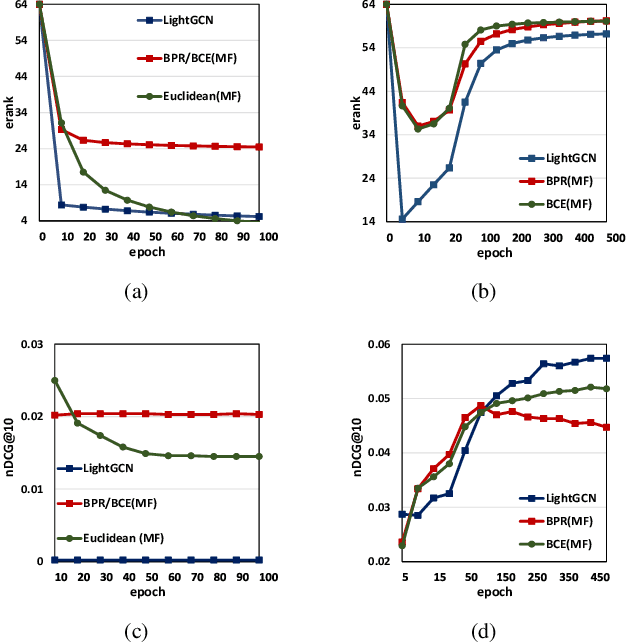
Modern recommender systems heavily rely on high-quality representations learned from high-dimensional sparse data. While significant efforts have been invested in designing powerful algorithms for extracting user preferences, the factors contributing to good representations have remained relatively unexplored. In this work, we shed light on an issue in the existing pair-wise learning paradigm (i.e., the embedding collapse problem), that the representations tend to span a subspace of the whole embedding space, leading to a suboptimal solution and reducing the model capacity. Specifically, optimization on observed interactions is equivalent to a low pass filter causing users/items to have the same representations and resulting in a complete collapse. While negative sampling acts as a high pass filter to alleviate the collapse by balancing the embedding spectrum, its effectiveness is only limited to certain losses, which still leads to an incomplete collapse. To tackle this issue, we propose a novel method called DirectSpec, acting as a reliable all pass filter to balance the spectrum distribution of the embeddings during training, ensuring that users/items effectively span the entire embedding space. Additionally, we provide a thorough analysis of DirectSpec from a decorrelation perspective and propose an enhanced variant, DirectSpec+, which employs self-paced gradients to optimize irrelevant samples more effectively. Moreover, we establish a close connection between DirectSpec+ and uniformity, demonstrating that contrastive learning (CL) can alleviate the collapse issue by indirectly balancing the spectrum. Finally, we implement DirectSpec and DirectSpec+ on two popular recommender models: MF and LightGCN. Our experimental results demonstrate its effectiveness and efficiency over competitive baselines.