 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVD-GCN: A Simplified Graph Convolution Paradigm for Recommendation
Aug 26, 2022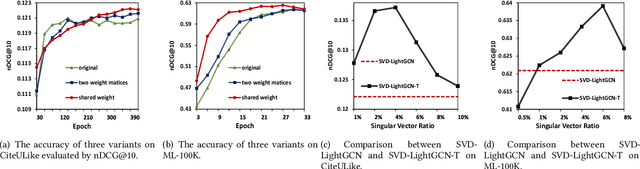
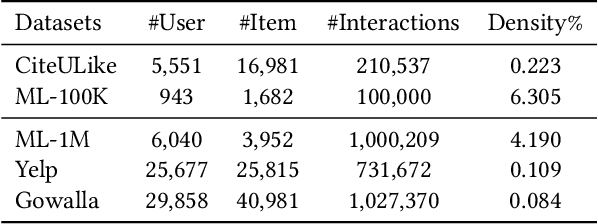
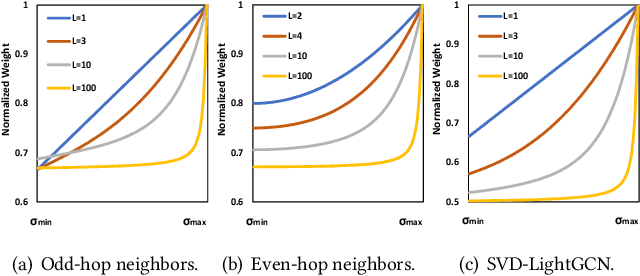
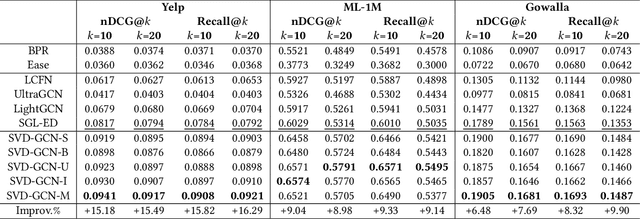
With the tremendous success of Graph Convolutional Networks (GCNs), they have been widely applied to recommender systems and have shown promising performance. However, most GCN-based methods rigorously stick to a common GCN learning paradigm and suffer from two limitations: (1) the limited scalability due to the high computational cost and slow training convergence; (2) the notorious over-smoothing issue which reduces performance as stacking graph convolution layers. We argue that the above limitations are due to the lack of a deep understanding of GCN-based methods. To this end, we first investigate what design makes GCN effective for recommendation. By simplifying LightGCN, we show the close connection between GCN-based and low-rank methods such as Singular Value Decomposition (SVD) and Matrix Factorization (MF), where stacking graph convolution layers is to learn a low-rank representation by emphasizing (suppressing) components with larger (smaller) singular values. Based on this observation, we replace the core design of GCN-based methods with a flexible truncated SVD and propose a simplified GCN learning paradigm dubbed SVD-GCN, which only exploits $K$-largest singular vectors for recommendation. To alleviate the over-smoothing issue, we propose a renormalization trick to adjust the singular value gap, resulting in significant improvement. Extensive experiments on three real-world datasets show that our proposed SVD-GCN not only significantly outperforms state-of-the-arts but also achieves over 100x and 10x speedups over LightGCN and MF, respectively.