 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomestic activities clustering from audio recordings using convolutional capsule autoencoder network
May 08, 2021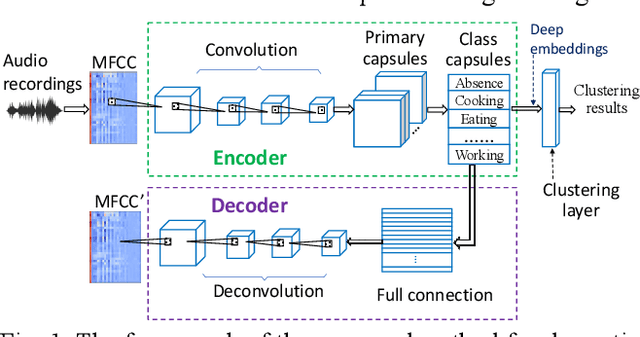


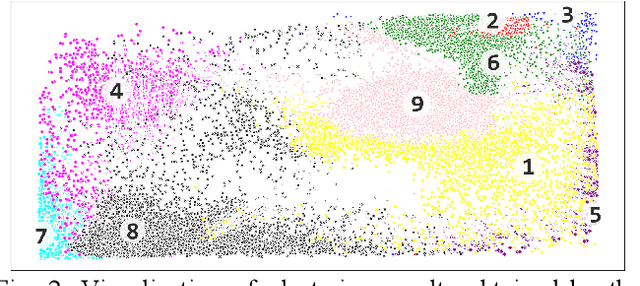
Recent efforts have been made on domestic activities classification from audio recordings, especially the works submitted to the challenge of DCASE (Detection and Classification of Acoustic Scenes and Events) since 2018. In contrast, few studies were done on domestic activities clustering, which is a newly emerging problem. Domestic activities clustering from audio recordings aims at merging audio clips which belong to the same class of domestic activity into a single cluster. Domestic activities clustering is an effective way for unsupervised estimation of daily activities performed in home environment. In this study, we propose a method for domestic activities clustering using a convolutional capsule autoencoder network (CCAN). In the method, the deep embeddings are learned by the autoencoder in the CCAN, while the deep embeddings which belong to the same class of domestic activities are merged into a single cluster by a clustering layer in the CCAN. Evaluated on a public dataset adopted in DCASE-2018 Task 5, the results show that the proposed method outperforms state-of-the-art methods in terms of the metrics of clustering accuracy and normalized mutual information.
Product Review Summarization based on Facet Identification and Sentence Clustering
Oct 07, 2011
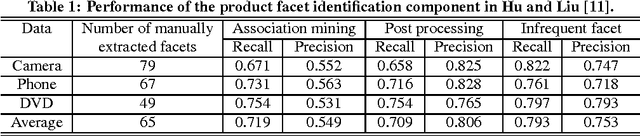
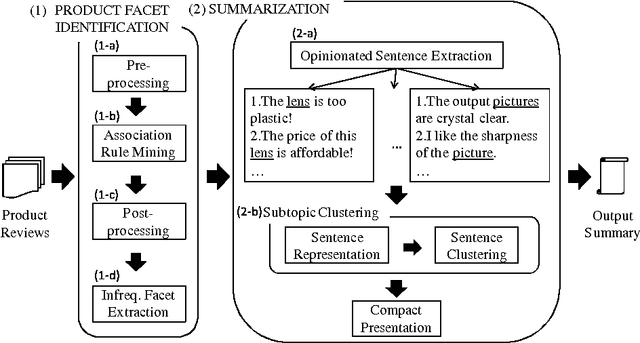
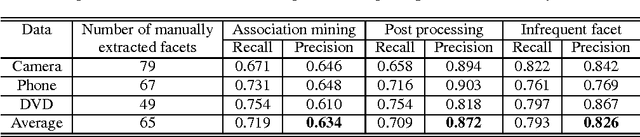
Product review nowadays has become an important source of information, not only for customers to find opinions about products easily and share their reviews with peers, but also for product manufacturers to get feedback on their products. As the number of product reviews grows, it becomes difficult for users to search and utilize these resources in an efficient way. In this work, we build a product review summarization system that can automatically process a large collection of reviews and aggregate them to generate a concise summary. More importantly, the drawback of existing product summarization systems is that they cannot provide the underlying reasons to justify users' opinions. In our method, we solve this problem by applying clustering, prior to selecting representative candidates for summarization.
A PDTB-Styled End-to-End Discourse Parser
Nov 03, 2010

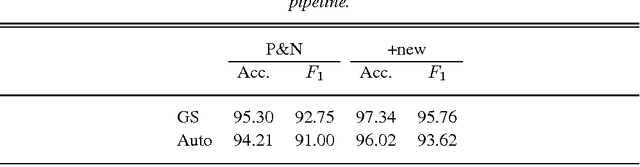

We have developed a full discourse parser in the Penn Discourse Treebank (PDTB) style. Our trained parser first identifies all discourse and non-discourse relations, locates and labels their arguments, and then classifies their relation types. When appropriate, the attribution spans to these relations are also determined. We present a comprehensive evaluation from both component-wise and error-cascading perspectives.
* 15 pages, 5 figures, 7 tables