 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Adaptive Keypoint Learning with Local-to-Global Geometric Aggregation for Category-Level Object Pose Estimation
Apr 21, 2025



Category-level object pose estimation aims to predict the 6D pose and size of previously unseen instances from predefined categories, requiring strong generalization across diverse object instances. Although many previous methods attempt to mitigate intra-class variations, they often struggle with instances exhibiting complex geometries or significant deviations from canonical shapes. To address this challenge, we propose INKL-Pose, a novel category-level object pose estimation framework that enables INstance-adaptive Keypoint Learning with local-to-global geometric aggregation. Specifically, our approach first predicts semantically consistent and geometric informative keypoints through an Instance-Adaptive Keypoint Generator, then refines them with: (1) a Local Keypoint Feature Aggregator capturing fine-grained geometries, and (2) a Global Keypoint Feature Aggregator using bidirectional Mamba for structural consistency. To enable bidirectional modeling in Mamba, we introduce a Feature Sequence Flipping strategy that preserves spatial coherence while constructing backward feature sequences. Additionally, we design a surface loss and a separation loss to enforce uniform coverage and spatial diversity in keypoint distribution. The generated keypoints are finally mapped to a canonical space for regressing the object's 6D pose and size. Extensive experiments on CAMERA25, REAL275, and HouseCat6D demonstrate that INKL-Pose achieves state-of-the-art performance and significantly outperforms existing methods.
Sur2f: A Hybrid Representation for High-Quality and Efficient Surface Reconstruction from Multi-view Images
Jan 08, 2024



Multi-view surface reconstruction is an ill-posed, inverse problem in 3D vision research. It involves modeling the geometry and appearance with appropriate surface representations. Most of the existing methods rely either on explicit meshes, using surface rendering of meshes for reconstruction, or on implicit field functions, using volume rendering of the fields for reconstruction. The two types of representations in fact have their respective merits. In this work, we propose a new hybrid representation, termed Sur2f, aiming to better benefit from both representations in a complementary manner. Technically, we learn two parallel streams of an implicit signed distance field and an explicit surrogate surface Sur2f mesh, and unify volume rendering of the implicit signed distance function (SDF) and surface rendering of the surrogate mesh with a shared, neural shader; the unified shading promotes their convergence to the same, underlying surface. We synchronize learning of the surrogate mesh by driving its deformation with functions induced from the implicit SDF. In addition, the synchronized surrogate mesh enables surface-guided volume sampling, which greatly improves the sampling efficiency per ray in volume rendering. We conduct thorough experiments showing that Sur$^2$f outperforms existing reconstruction methods and surface representations, including hybrid ones, in terms of both recovery quality and recovery efficiency.
HelixSurf: A Robust and Efficient Neural Implicit Surface Learning of Indoor Scenes with Iterative Intertwined Regularization
Mar 01, 2023Recovery of an underlying scene geometry from multiview images stands as a long-time challenge in computer vision research. The recent promise leverages neural implicit surface learning and differentiable volume rendering, and achieves both the recovery of scene geometry and synthesis of novel views, where deep priors of neural models are used as an inductive smoothness bias. While promising for object-level surfaces, these methods suffer when coping with complex scene surfaces. In the meanwhile, traditional multi-view stereo can recover the geometry of scenes with rich textures, by globally optimizing the local, pixel-wise correspondences across multiple views. We are thus motivated to make use of the complementary benefits from the two strategies, and propose a method termed Helix-shaped neural implicit Surface learning or HelixSurf; HelixSurf uses the intermediate prediction from one strategy as the guidance to regularize the learning of the other one, and conducts such intertwined regularization iteratively during the learning process. We also propose an efficient scheme for differentiable volume rendering in HelixSurf. Experiments on surface reconstruction of indoor scenes show that our method compares favorably with existing methods and is orders of magnitude faster, even when some of existing methods are assisted with auxiliary training data. The source code is available at https://github.com/Gorilla-Lab-SCUT/HelixSurf.
Surface Reconstruction from Point Clouds: A Survey and a Benchmark
May 05, 2022



Reconstruction of a continuous surface of two-dimensional manifold from its raw, discrete point cloud observation is a long-standing problem. The problem is technically ill-posed, and becomes more difficult considering that various sensing imperfections would appear in the point clouds obtained by practical depth scanning. In literature, a rich set of methods has been proposed, and reviews of existing methods are also provided. However, existing reviews are short of thorough investigations on a common benchmark. The present paper aims to review and benchmark existing methods in the new era of deep learning surface reconstruction. To this end, we contribute a large-scale benchmarking dataset consisting of both synthetic and real-scanned data; the benchmark includes object- and scene-level surfaces and takes into account various sensing imperfections that are commonly encountered in practical depth scanning. We conduct thorough empirical studies by comparing existing methods on the constructed benchmark, and pay special attention on robustness of existing methods against various scanning imperfections; we also study how different methods generalize in terms of reconstructing complex surface shapes. Our studies help identify the best conditions under which different methods work, and suggest some empirical findings. For example, while deep learning methods are increasingly popular, our systematic studies suggest that, surprisingly, a few classical methods perform even better in terms of both robustness and generalization; our studies also suggest that the practical challenges of misalignment of point sets from multi-view scanning, missing of surface points, and point outliers remain unsolved by all the existing surface reconstruction methods. We expect that the benchmark and our studies would be valuable both for practitioners and as a guidance for new innovations in future research.
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 30, 2021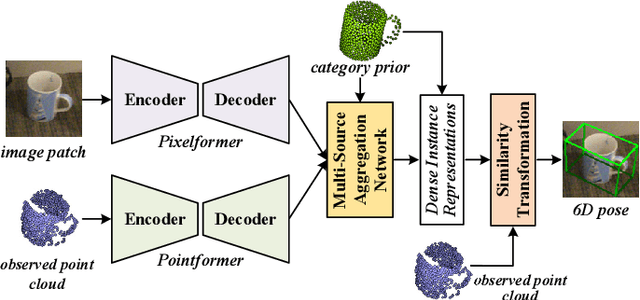


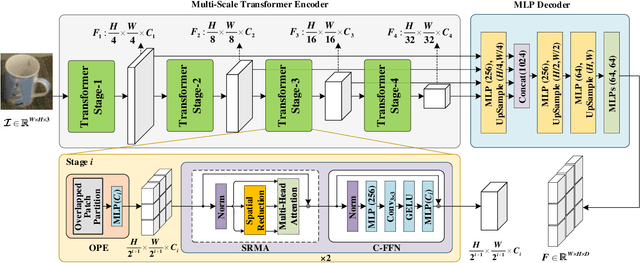
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.
Domestic activities clustering from audio recordings using convolutional capsule autoencoder network
May 08, 2021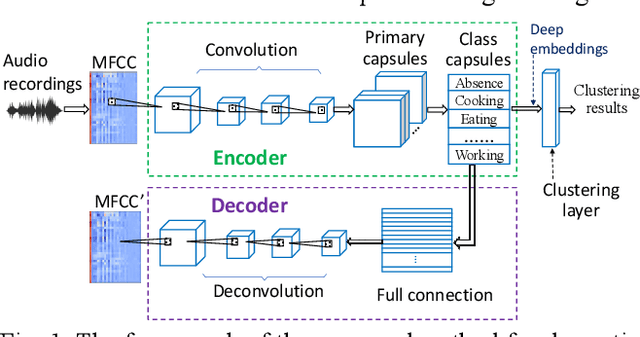


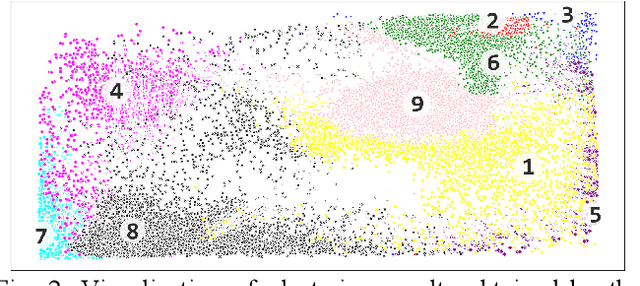
Recent efforts have been made on domestic activities classification from audio recordings, especially the works submitted to the challenge of DCASE (Detection and Classification of Acoustic Scenes and Events) since 2018. In contrast, few studies were done on domestic activities clustering, which is a newly emerging problem. Domestic activities clustering from audio recordings aims at merging audio clips which belong to the same class of domestic activity into a single cluster. Domestic activities clustering is an effective way for unsupervised estimation of daily activities performed in home environment. In this study, we propose a method for domestic activities clustering using a convolutional capsule autoencoder network (CCAN). In the method, the deep embeddings are learned by the autoencoder in the CCAN, while the deep embeddings which belong to the same class of domestic activities are merged into a single cluster by a clustering layer in the CCAN. Evaluated on a public dataset adopted in DCASE-2018 Task 5, the results show that the proposed method outperforms state-of-the-art methods in terms of the metrics of clustering accuracy and normalized mutual information.