 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Adaptive Keypoint Learning with Local-to-Global Geometric Aggregation for Category-Level Object Pose Estimation
Apr 21, 2025



Category-level object pose estimation aims to predict the 6D pose and size of previously unseen instances from predefined categories, requiring strong generalization across diverse object instances. Although many previous methods attempt to mitigate intra-class variations, they often struggle with instances exhibiting complex geometries or significant deviations from canonical shapes. To address this challenge, we propose INKL-Pose, a novel category-level object pose estimation framework that enables INstance-adaptive Keypoint Learning with local-to-global geometric aggregation. Specifically, our approach first predicts semantically consistent and geometric informative keypoints through an Instance-Adaptive Keypoint Generator, then refines them with: (1) a Local Keypoint Feature Aggregator capturing fine-grained geometries, and (2) a Global Keypoint Feature Aggregator using bidirectional Mamba for structural consistency. To enable bidirectional modeling in Mamba, we introduce a Feature Sequence Flipping strategy that preserves spatial coherence while constructing backward feature sequences. Additionally, we design a surface loss and a separation loss to enforce uniform coverage and spatial diversity in keypoint distribution. The generated keypoints are finally mapped to a canonical space for regressing the object's 6D pose and size. Extensive experiments on CAMERA25, REAL275, and HouseCat6D demonstrate that INKL-Pose achieves state-of-the-art performance and significantly outperforms existing methods.
Kernel Multigrid: Accelerate Back-fitting via Sparse Gaussian Process Regression
Mar 30, 2024Additive Gaussian Processes (GPs) are popular approaches for nonparametric feature selection. The common training method for these models is Bayesian Back-fitting. However, the convergence rate of Back-fitting in training additive GPs is still an open problem. By utilizing a technique called Kernel Packets (KP), we prove that the convergence rate of Back-fitting is no faster than $(1-\mathcal{O}(\frac{1}{n}))^t$, where $n$ and $t$ denote the data size and the iteration number, respectively. Consequently, Back-fitting requires a minimum of $\mathcal{O}(n\log n)$ iterations to achieve convergence. Based on KPs, we further propose an algorithm called Kernel Multigrid (KMG). This algorithm enhances Back-fitting by incorporating a sparse Gaussian Process Regression (GPR) to process the residuals after each Back-fitting iteration. It is applicable to additive GPs with both structured and scattered data. Theoretically, we prove that KMG reduces the required iterations to $\mathcal{O}(\log n)$ while preserving the time and space complexities at $\mathcal{O}(n\log n)$ and $\mathcal{O}(n)$ per iteration, respectively. Numerically, by employing a sparse GPR with merely 10 inducing points, KMG can produce accurate approximations of high-dimensional targets within 5 iterations.
Regret Optimality of GP-UCB
Dec 03, 2023Gaussian Process Upper Confidence Bound (GP-UCB) is one of the most popular methods for optimizing black-box functions with noisy observations, due to its simple structure and superior performance. Its empirical successes lead to a natural, yet unresolved question: Is GP-UCB regret optimal? In this paper, we offer the first generally affirmative answer to this important open question in the Bayesian optimization literature. We establish new upper bounds on both the simple and cumulative regret of GP-UCB when the objective function to optimize admits certain smoothness property. These upper bounds match the known minimax lower bounds (up to logarithmic factors independent of the feasible region's dimensionality) for optimizing functions with the same smoothness. Intriguingly, our findings indicate that, with the same level of exploration, GP-UCB can simultaneously achieve optimality in both simple and cumulative regret. The crux of our analysis hinges on a refined uniform error bound for online estimation of functions in reproducing kernel Hilbert spaces. This error bound, which we derive from empirical process theory, is of independent interest, and its potential applications may reach beyond the scope of this study.
Representing Additive Gaussian Processes by Sparse Matrices
Apr 29, 2023Among generalized additive models, additive Mat\'ern Gaussian Processes (GPs) are one of the most popular for scalable high-dimensional problems. Thanks to their additive structure and stochastic differential equation representation, back-fitting-based algorithms can reduce the time complexity of computing the posterior mean from $O(n^3)$ to $O(n\log n)$ time where $n$ is the data size. However, generalizing these algorithms to efficiently compute the posterior variance and maximum log-likelihood remains an open problem. In this study, we demonstrate that for Additive Mat\'ern GPs, not only the posterior mean, but also the posterior variance, log-likelihood, and gradient of these three functions can be represented by formulas involving only sparse matrices and sparse vectors. We show how to use these sparse formulas to generalize back-fitting-based algorithms to efficiently compute the posterior mean, posterior variance, log-likelihood, and gradient of these three functions for additive GPs, all in $O(n \log n)$ time. We apply our algorithms to Bayesian optimization and propose efficient algorithms for posterior updates, hyperparameters learning, and computations of the acquisition function and its gradient in Bayesian optimization. Given the posterior, our algorithms significantly reduce the time complexity of computing the acquisition function and its gradient from $O(n^2)$ to $O(\log n)$ for general learning rate, and even to $O(1)$ for small learning rate.
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 30, 2021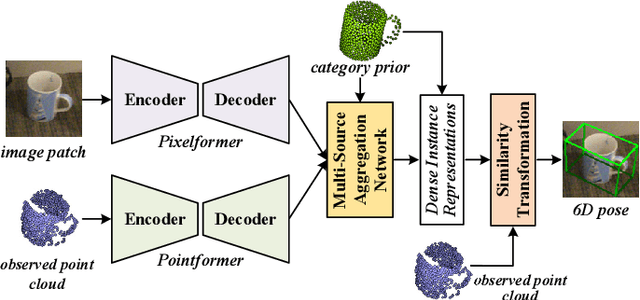


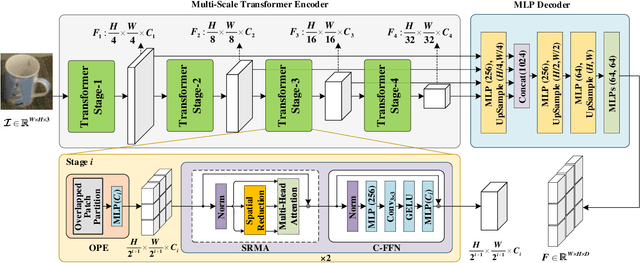
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.