 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Anomaly Detection with Mondrian P{ó}lya Forests on Data Streams
Aug 04, 2020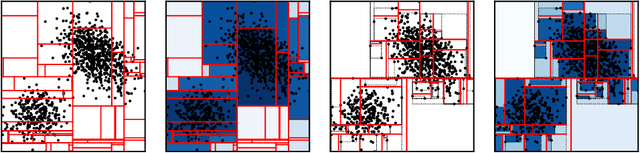
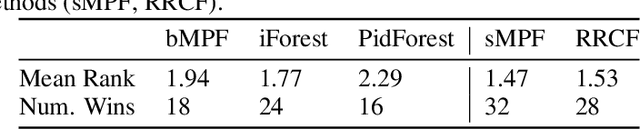
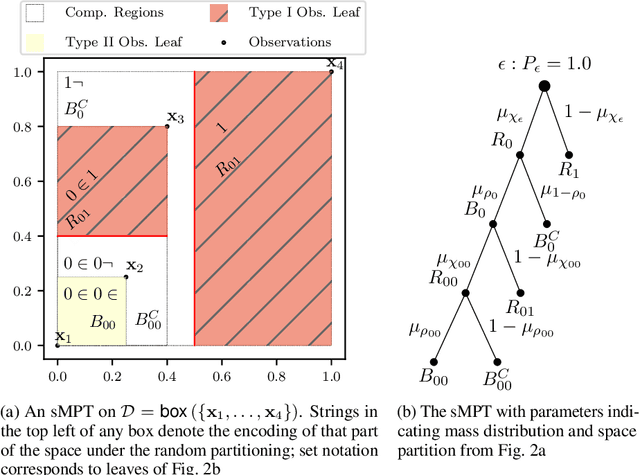
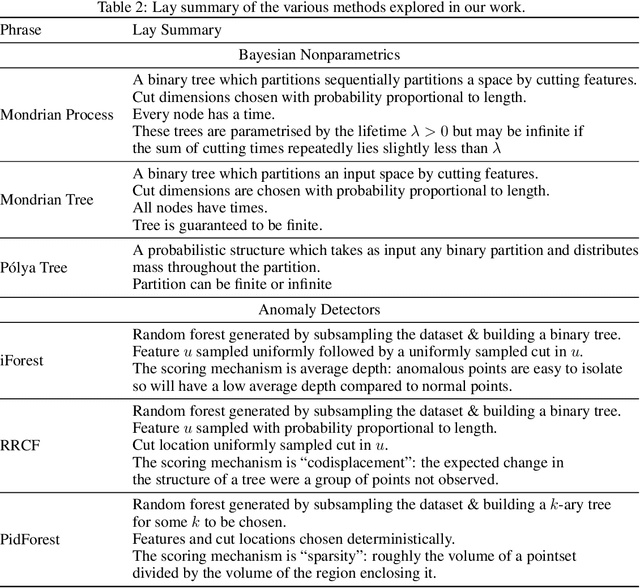
Anomaly detection at scale is an extremely challenging problem of great practicality. When data is large and high-dimensional, it can be difficult to detect which observations do not fit the expected behaviour. Recent work has coalesced on variations of (random) $k$\emph{d-trees} to summarise data for anomaly detection. However, these methods rely on ad-hoc score functions that are not easy to interpret, making it difficult to asses the severity of the detected anomalies or select a reasonable threshold in the absence of labelled anomalies. To solve these issues, we contextualise these methods in a probabilistic framework which we call the Mondrian \Polya{} Forest for estimating the underlying probability density function generating the data and enabling greater interpretability than prior work. In addition, we develop a memory efficient variant able to operate in the modern streaming environments. Our experiments show that these methods achieves state-of-the-art performance while providing statistically interpretable anomaly scores.
Tomographic Auto-Encoder: Unsupervised Bayesian Recovery of Corrupted Data
Jun 30, 2020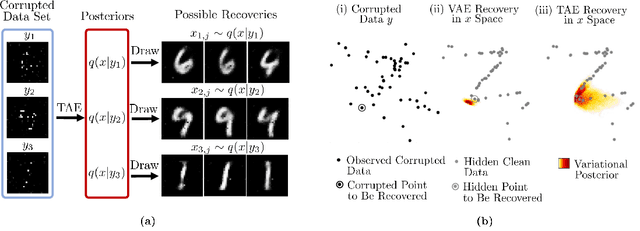

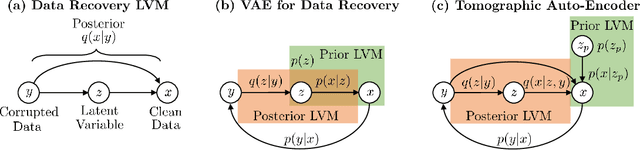
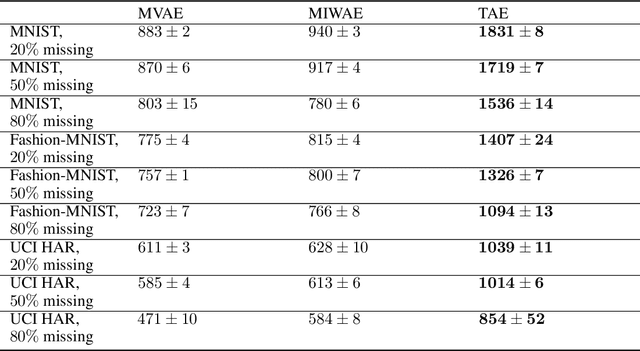
We propose a new probabilistic method for unsupervised recovery of corrupted data. Given a large ensemble of degraded samples, our method recovers accurate posteriors of clean values, allowing the exploration of the manifold of possible reconstructed data and hence characterising the underlying uncertainty. In this setting, direct application of classical variational methods often gives rise to collapsed densities that do not adequately explore the solution space. Instead, we derive our novel reduced entropy condition approximate inference method that results in rich posteriors. We test our model in a data recovery task under the common setting of missing values and noise, demonstrating superior performance to existing variational methods for imputation and de-noising with different real data sets. We further show higher classification accuracy after imputation, proving the advantage of propagating uncertainty to downstream tasks with our model.
Empirical Bayes Transductive Meta-Learning with Synthetic Gradients
Apr 27, 2020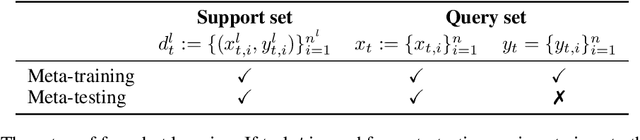
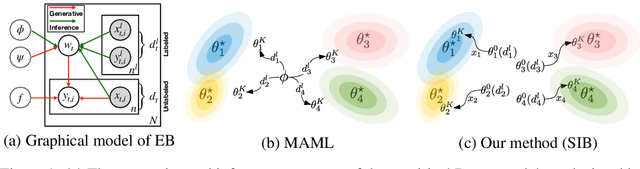
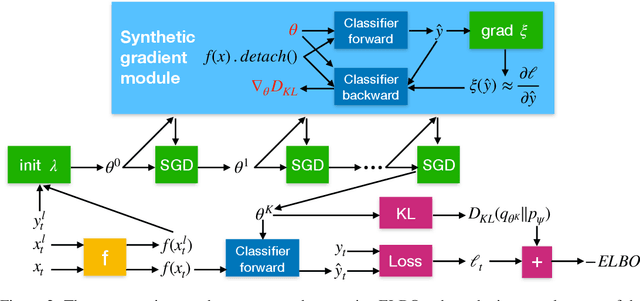
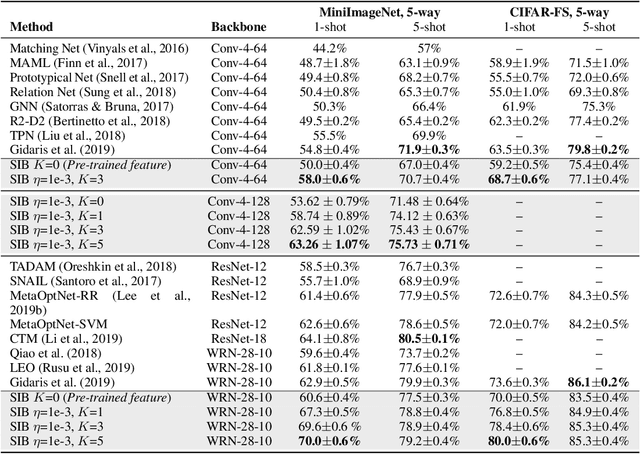
We propose a meta-learning approach that learns from multiple tasks in a transductive setting, by leveraging the unlabeled query set in addition to the support set to generate a more powerful model for each task. To develop our framework, we revisit the empirical Bayes formulation for multi-task learning. The evidence lower bound of the marginal log-likelihood of empirical Bayes decomposes as a sum of local KL divergences between the variational posterior and the true posterior on the query set of each task. We derive a novel amortized variational inference that couples all the variational posteriors via a meta-model, which consists of a synthetic gradient network and an initialization network. Each variational posterior is derived from synthetic gradient descent to approximate the true posterior on the query set, although where we do not have access to the true gradient. Our results on the Mini-ImageNet and CIFAR-FS benchmarks for episodic few-shot classification outperform previous state-of-the-art methods. Besides, we conduct two zero-shot learning experiments to further explore the potential of the synthetic gradient.
Transferring Knowledge across Learning Processes
Dec 03, 2018


In complex transfer learning scenarios new tasks might not be tightly linked to previous tasks. Approaches that transfer information contained only in the final parameters of a source model will therefore struggle. Instead, transfer learning at a higher level of abstraction is needed. We propose Leap, a framework that achieves this by transferring knowledge across learning processes. We associate each task with a manifold on which the training process travels from initialization to final parameters and construct a meta learning objective that minimizes the expected length of this path. Our framework leverages only information obtained during training and can be computed on the fly at negligible cost. We demonstrate that our framework outperforms competing methods, both in meta learning and transfer learning, on a set of computer vision tasks. Finally, we demonstrate that Leap can transfer knowledge across learning processes in demanding Reinforcement Learning environments (Atari) that involve millions of gradient steps.
Bayesian Nonparametric Crowdsourcing
Jul 18, 2014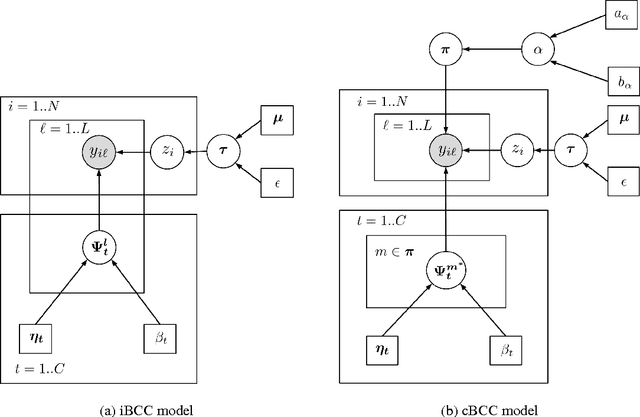

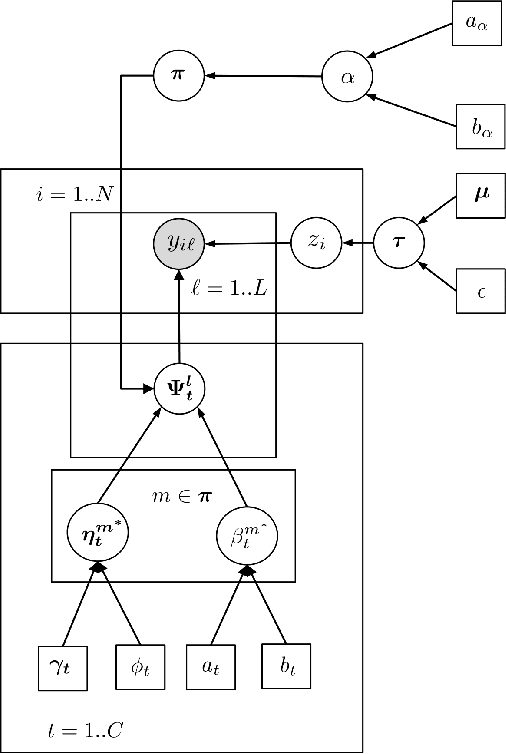

Crowdsourcing has been proven to be an effective and efficient tool to annotate large datasets. User annotations are often noisy, so methods to combine the annotations to produce reliable estimates of the ground truth are necessary. We claim that considering the existence of clusters of users in this combination step can improve the performance. This is especially important in early stages of crowdsourcing implementations, where the number of annotations is low. At this stage there is not enough information to accurately estimate the bias introduced by each annotator separately, so we have to resort to models that consider the statistical links among them. In addition, finding these clusters is interesting in itself as knowing the behavior of the pool of annotators allows implementing efficient active learning strategies. Based on this, we propose in this paper two new fully unsupervised models based on a Chinese Restaurant Process (CRP) prior and a hierarchical structure that allows inferring these groups jointly with the ground truth and the properties of the users. Efficient inference algorithms based on Gibbs sampling with auxiliary variables are proposed. Finally, we perform experiments, both on synthetic and real databases, to show the advantages of our models over state-of-the-art algorithms.