 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Anomaly Detection with Mondrian P{ó}lya Forests on Data Streams
Paper and Code
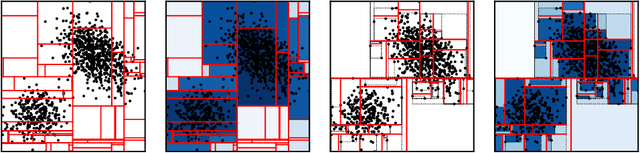
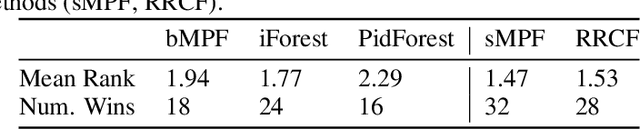
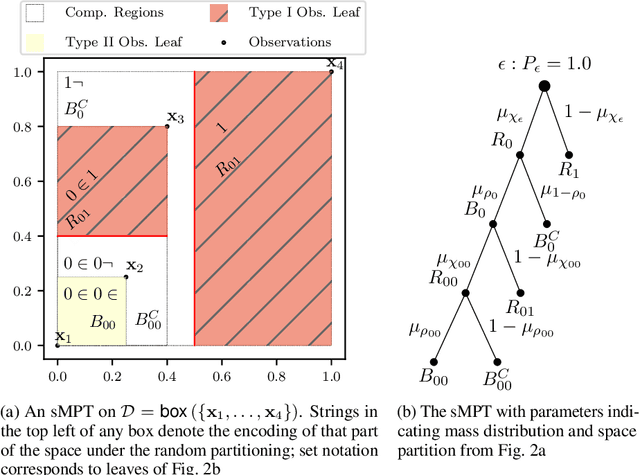
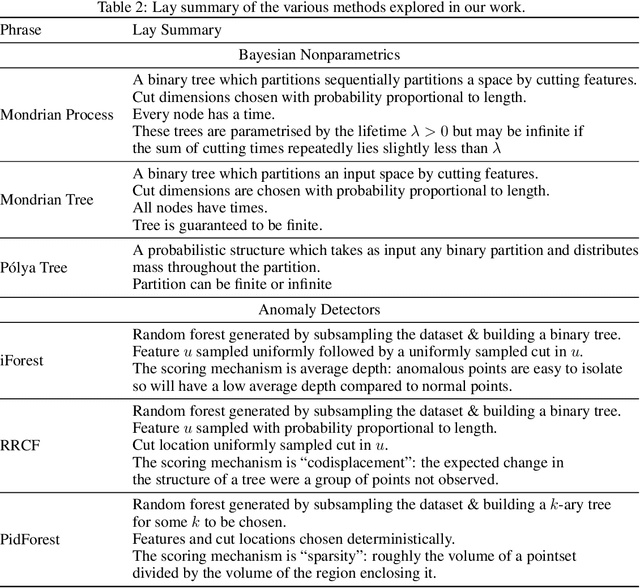
Anomaly detection at scale is an extremely challenging problem of great practicality. When data is large and high-dimensional, it can be difficult to detect which observations do not fit the expected behaviour. Recent work has coalesced on variations of (random) $k$\emph{d-trees} to summarise data for anomaly detection. However, these methods rely on ad-hoc score functions that are not easy to interpret, making it difficult to asses the severity of the detected anomalies or select a reasonable threshold in the absence of labelled anomalies. To solve these issues, we contextualise these methods in a probabilistic framework which we call the Mondrian \Polya{} Forest for estimating the underlying probability density function generating the data and enabling greater interpretability than prior work. In addition, we develop a memory efficient variant able to operate in the modern streaming environments. Our experiments show that these methods achieves state-of-the-art performance while providing statistically interpretable anomaly scores.