 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRidge Regression with Frequent Directions: Statistical and Optimization Perspectives
Nov 06, 2020



Despite its impressive theory \& practical performance, Frequent Directions (\acrshort{fd}) has not been widely adopted for large-scale regression tasks. Prior work has shown randomized sketches (i) perform worse in estimating the covariance matrix of the data than \acrshort{fd}; (ii) incur high error when estimating the bias and/or variance on sketched ridge regression. We give the first constant factor relative error bounds on the bias \& variance for sketched ridge regression using \acrshort{fd}. We complement these statistical results by showing that \acrshort{fd} can be used in the optimization setting through an iterative scheme which yields high-accuracy solutions. This improves on randomized approaches which need to compromise the need for a new sketch every iteration with speed of convergence. In both settings, we also show using \emph{Robust Frequent Directions} further enhances performance.
Interpretable Anomaly Detection with Mondrian P{ó}lya Forests on Data Streams
Aug 04, 2020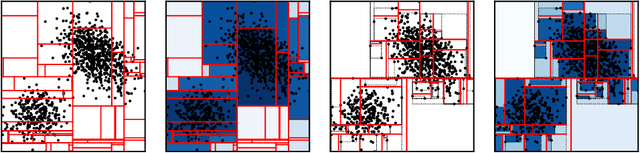
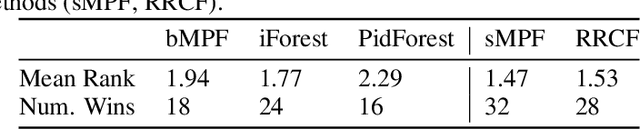
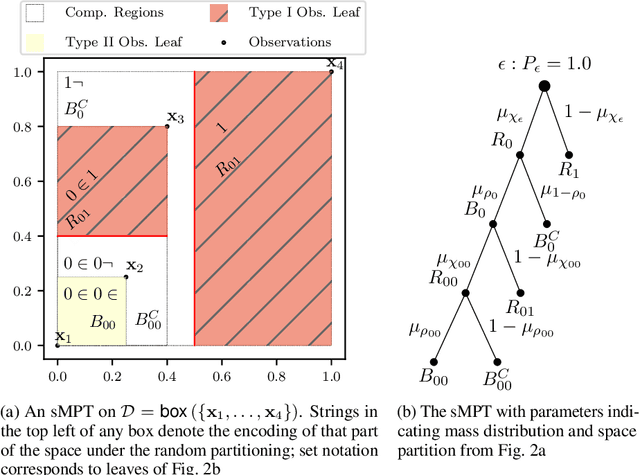
Anomaly detection at scale is an extremely challenging problem of great practicality. When data is large and high-dimensional, it can be difficult to detect which observations do not fit the expected behaviour. Recent work has coalesced on variations of (random) $k$\emph{d-trees} to summarise data for anomaly detection. However, these methods rely on ad-hoc score functions that are not easy to interpret, making it difficult to asses the severity of the detected anomalies or select a reasonable threshold in the absence of labelled anomalies. To solve these issues, we contextualise these methods in a probabilistic framework which we call the Mondrian \Polya{} Forest for estimating the underlying probability density function generating the data and enabling greater interpretability than prior work. In addition, we develop a memory efficient variant able to operate in the modern streaming environments. Our experiments show that these methods achieves state-of-the-art performance while providing statistically interpretable anomaly scores.
Similarity of Neural Networks with Gradients
Mar 25, 2020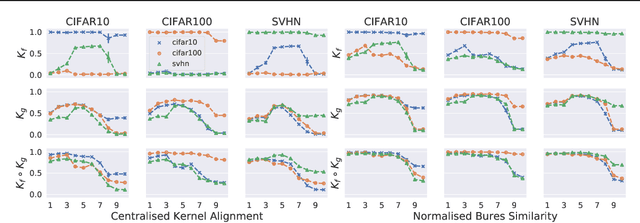
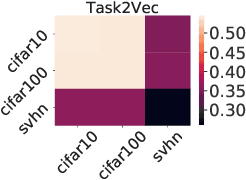
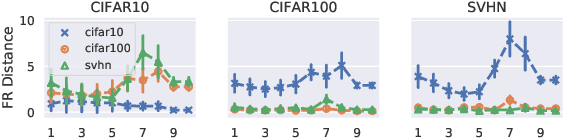
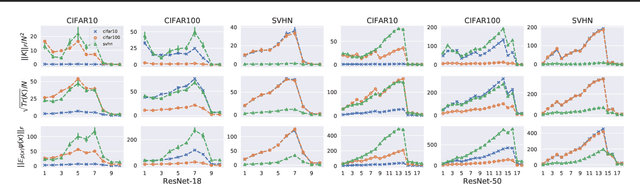
A suitable similarity index for comparing learnt neural networks plays an important role in understanding the behaviour of the highly-nonlinear functions, and can provide insights on further theoretical analysis and empirical studies. We define two key steps when comparing models: firstly, the representation abstracted from the learnt model, where we propose to leverage both feature vectors and gradient ones (which are largely ignored in prior work) into designing the representation of a neural network. Secondly, we define the employed similarity index which gives desired invariance properties, and we facilitate the chosen ones with sketching techniques for comparing various datasets efficiently. Empirically, we show that the proposed approach provides a state-of-the-art method for computing similarity of neural networks that are trained independently on different datasets and the tasks defined by the datasets.
Iterative Hessian Sketch in Input Sparsity Time
Oct 30, 2019

Scalable algorithms to solve optimization and regression tasks even approximately, are needed to work with large datasets. In this paper we study efficient techniques from matrix sketching to solve a variety of convex constrained regression problems. We adopt "Iterative Hessian Sketching" (IHS) and show that the fast CountSketch and sparse Johnson-Lindenstrauss Transforms yield state-of-the-art accuracy guarantees under IHS, while drastically improving the time cost. As a result, we obtain significantly faster algorithms for constrained regression, for both sparse and dense inputs. Our empirical results show that we can summarize data roughly 100x faster for sparse data, and, surprisingly, 10x faster on dense data! Consequently, solutions accurate to within machine precision of the optimal solution can be found much faster than the previous state of the art.