 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity of Neural Networks with Gradients
Paper and Code
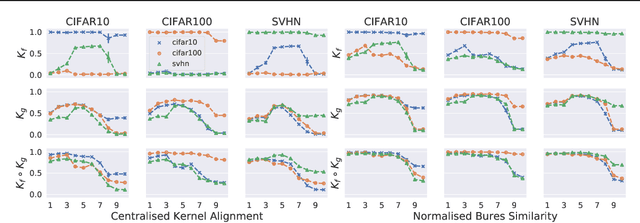
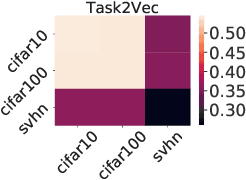
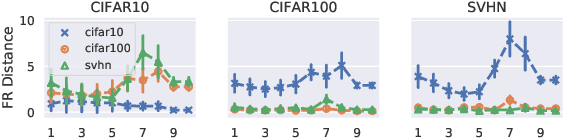
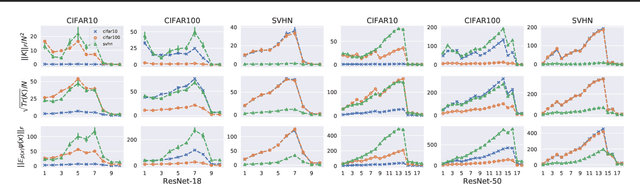
A suitable similarity index for comparing learnt neural networks plays an important role in understanding the behaviour of the highly-nonlinear functions, and can provide insights on further theoretical analysis and empirical studies. We define two key steps when comparing models: firstly, the representation abstracted from the learnt model, where we propose to leverage both feature vectors and gradient ones (which are largely ignored in prior work) into designing the representation of a neural network. Secondly, we define the employed similarity index which gives desired invariance properties, and we facilitate the chosen ones with sketching techniques for comparing various datasets efficiently. Empirically, we show that the proposed approach provides a state-of-the-art method for computing similarity of neural networks that are trained independently on different datasets and the tasks defined by the datasets.