 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Jun 18, 2024

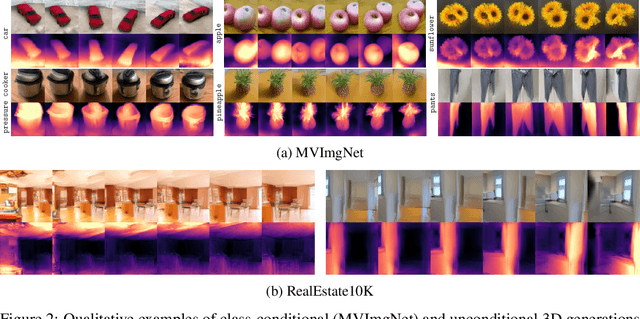
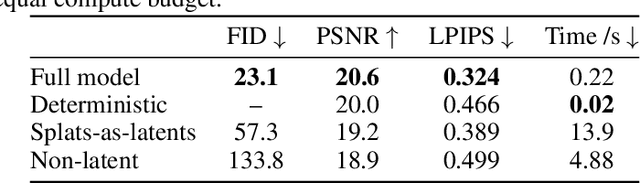
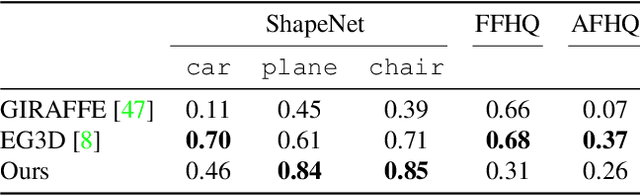
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation
Nov 17, 2022


Diffusion models currently achieve state-of-the-art performance for both conditional and unconditional image generation. However, so far, image diffusion models do not support tasks required for 3D understanding, such as view-consistent 3D generation or single-view object reconstruction. In this paper, we present RenderDiffusion as the first diffusion model for 3D generation and inference that can be trained using only monocular 2D supervision. At the heart of our method is a novel image denoising architecture that generates and renders an intermediate three-dimensional representation of a scene in each denoising step. This enforces a strong inductive structure into the diffusion process that gives us a 3D consistent representation while only requiring 2D supervision. The resulting 3D representation can be rendered from any viewpoint. We evaluate RenderDiffusion on ShapeNet and Clevr datasets and show competitive performance for generation of 3D scenes and inference of 3D scenes from 2D images. Additionally, our diffusion-based approach allows us to use 2D inpainting to edit 3D scenes. We believe that our work promises to enable full 3D generation at scale when trained on massive image collections, thus circumventing the need to have large-scale 3D model collections for supervision.